Comparación de rendimiento de Direct Lake en OneLake entre el lakehouse y el warehouse
En este post comparo el rendimiento en Direct Lake de varias configuraciones de tablas Delta en un lakehouse y en un warehouse.
Es una continuación de los dos post anteriores (post 1, post 2), pero esta vez no se han ejecutado consultas T-SQL sino consultas DAX sobre modelos semánticos Direct Lake en OneLake.
Para realizar estas pruebas se ha creado una nueva área de trabajo con capacidad Fabric de prueba F64.
Al igual que en los posts anteriores he contado con la valiosa ayuda de GitHub Copilot CLI, con el mismo flujo de trabajo que he explicado en el primer post de la serie.
El código y las instrucciones las puedes consultar en el repositorio en GitHub https://github.com/dataxbi/fablab-direct-lake.
Preparación de los datos
Se crearon 6 modelos semánticos en modo de almacenamiento Direct Lake en OneLake, a partir de los datos y escenarios (esquemas) utilizados en los posts anteriores.
| Nombre del modelo semántico | Tipo de fuente | Esquema |
|---|---|---|
SM_DL_LH_Default |
Direct Lake → Lakehouse | benchmark_default |
SM_DL_LH_Partitioned |
Direct Lake → Lakehouse | benchmark_partitioned |
SM_DL_LH_VOrder |
Direct Lake → Lakehouse | benchmark_vorder |
SM_DL_WH |
Direct Lake → Warehouse | benchmark |
SM_DL_WH_Frag |
Direct Lake → Warehouse | benchmark_frag |
SM_DL_LH_Frag |
Direct Lake → Lakehouse | benchmark_frag ⚠️ excluido (refresco falla) |
En el listado anterior hay una nota indicando que para el último modelo semántico falló el refresco de los datos, que en el caso de Direct Lake es en realidad el enmarcado (framing) y que consiste en actualizar solo los metadatos de las tablas Delta. La causa del fallo es que en el escenario del lakehouse fragmentado la tabla de hechos tiene muchos archivos Parquet pequeños (29.000 archivos 😢), por lo que está muy por encima del límite para una capacidad F64 que son 5.000 archivos Parquet por tabla Delta. Por tanto, este modelo se excluyó de las pruebas.
Sin embargo, esto no sucede en el modelo semántico que utiliza las tablas fragmentadas del warehouse y la razón es que en este caso Fabric se encarga de ejecutar OPTIMIZE automáticamente, por lo que se agruparon varios archivos Parquet en uno solo. En una investigación que hice con la ayuda de Copilot encontré que en el warehouse los archivos Parquet se redujeron de casi 29.000 a 149 😎.
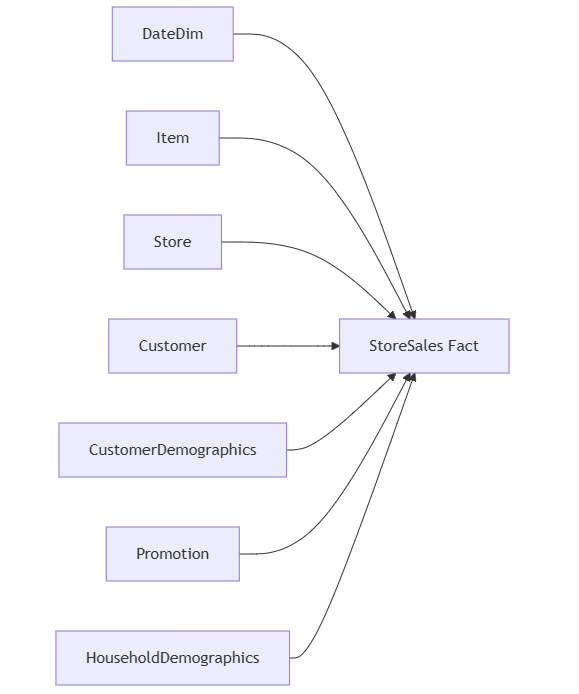
Todos los modelos semánticos tienen la misma estructura, que se muestra en la imagen. En el repositorio de GitHub está la definición en TMDL.
Consultas DAX
Las consultas DAX que se utilizaron para medir el rendimiento se crearon a partir de las consultas T-SQL de las pruebas anteriores, que a su vez están inspiradas en consultas de TPC-DS.
-
Q1 — Agregación simple: https://github.com/dataxbi/fablab-direct-lake/blob/main/dax/q01_simple_agg.dax
-
Q2 — Join grande (star schema): https://github.com/dataxbi/fablab-direct-lake/blob/main/dax/q02_large_join.dax
-
Q3 — Top N con filtros selectivos: https://github.com/dataxbi/fablab-direct-lake/blob/main/dax/q03_top_n_selective.dax
-
Q4 — Query compleja tipo TPC-DS real: https://github.com/dataxbi/fablab-direct-lake/blob/main/dax/q04_complex_tpcds.dax
-
Q5 — Función ventana analítica: https://github.com/dataxbi/fablab-direct-lake/blob/main/dax/q05_window_function.dax
Para crear las consultas DAX, utilicé primero el modelo Claude Opus 4.7 para traducir las consultas T-SQL. Luego cambié al modelo GPT-5.5 y le pedí que las revisara. Y finalmente las revisé yo.
Ambos modelos LLM se conectaron a uno de los modelos semánticos para validar que las consultas se ejecutaban bien. Esta ejecución sirvió para detectar que en una de las consultas había un filtro con un valor que no existía en la dimensión, y fue corregido por Claude Opus. En la revisión hecha por GPT sugirió cambiar un FILTER dentro de un SUMMARIZECOLUMNS por un TREATAS, lo que me pareció muy bien.
En mi revisión lo único que encontré fue un par de SUMMARIZE donde se añadían directamente columnas con expresiones y lo cambié por ADDCOLUMNS / SUMMARIZE.
Pruebas realizadas
Para las pruebas se creó un script que utiliza la API REST de Power BI para hacer lo siguiente:
- Refrescar los 5 modelos semánticos para asegurar que no haya datos cargados en memoria.
- Ejecutar una vez las 5 consultas DAX en cada uno de los 5 modelos semánticos. (Ejecución en frío.)
- Ejecutar 3 veces las 5 consultas DAX en cada uno de los 5 modelos semánticos. (Ejecución en caliente.)
En total se hicieron 100 ejecuciones de las consultas DAX.
Los resultados de estas pruebas se guardaron en archivos CSV.
También se creó un notebook Python para analizar los resultados de estas ejecuciones.
Resultados
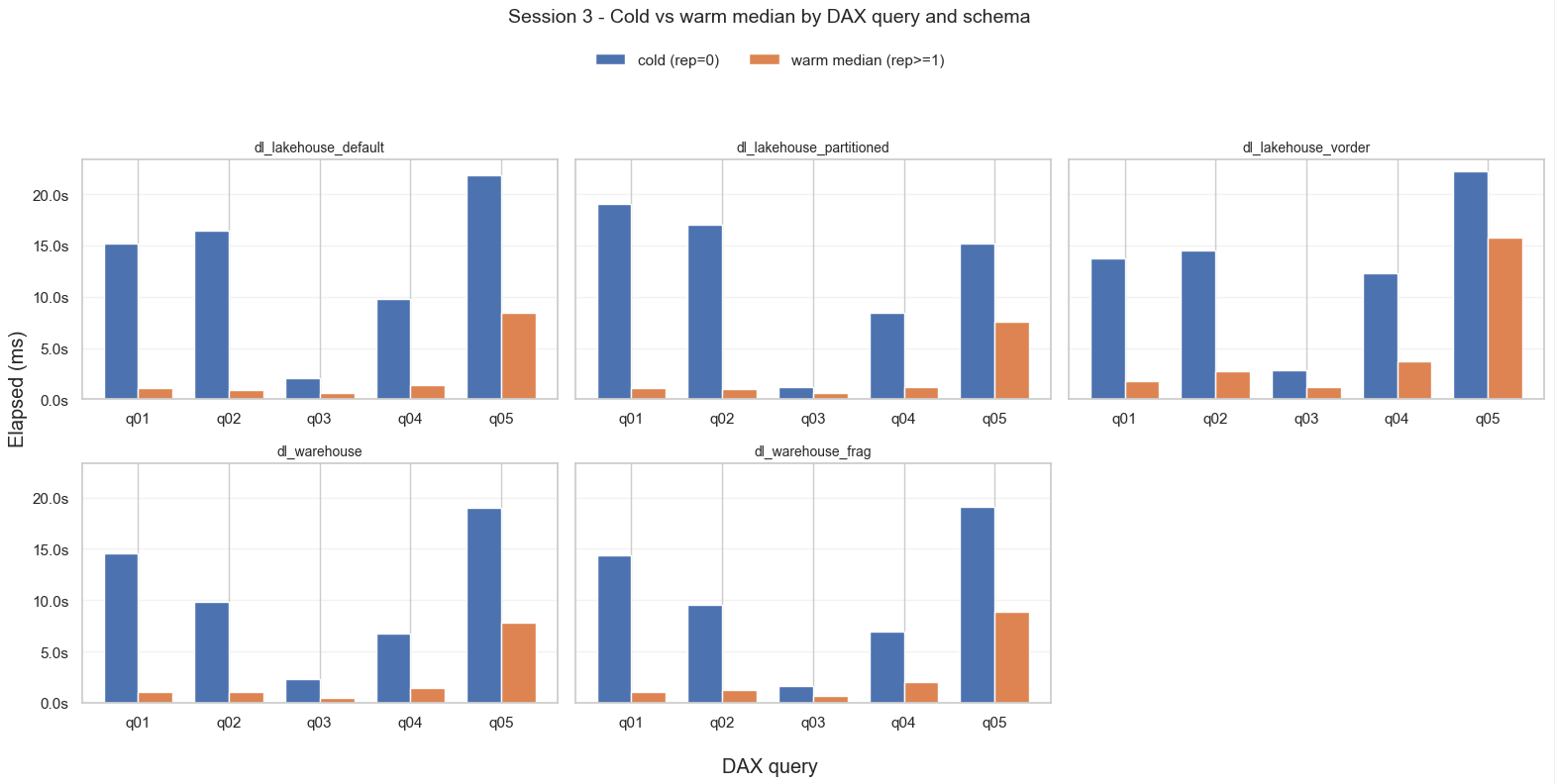
👇 El primer resultado es la comparación del tiempo de ejecución de las consultas en frío (barras izquierdas, azules) vs. la mediana del tiempo de ejecución de las consultas en caliente (barras derechas, naranjas) para cada uno de los 5 modelos semánticos.
Aquí resalta lo obvio: Las consultas en frío son más lentas en todos los casos.
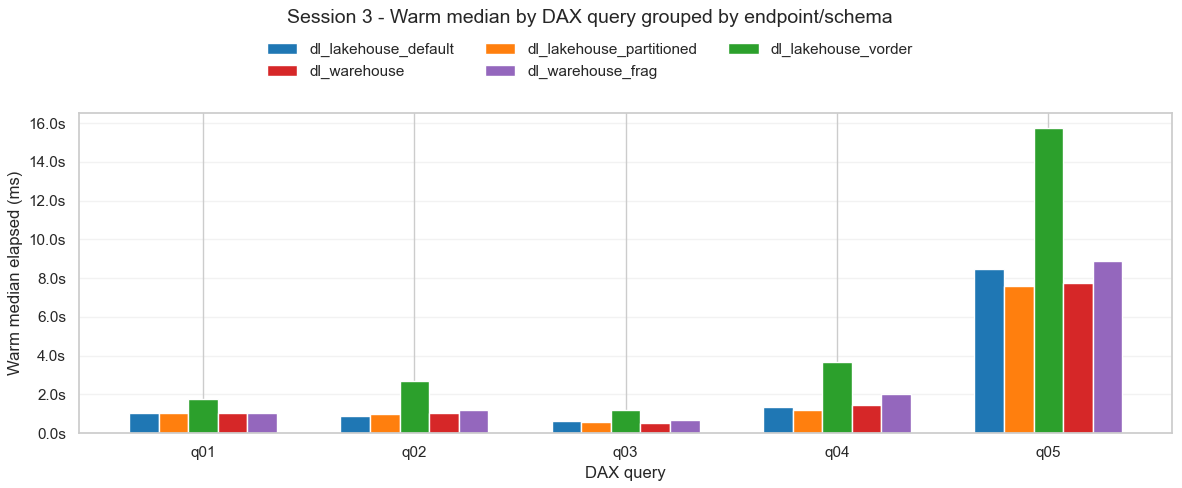
👇 En el segundo gráfico se analizan solo las ejecuciones en caliente, mostrándose para cada consulta DAX la mediana de las 3 ejecuciones en cada uno de los 5 modelos semánticos.
Dentro de cada consulta los tiempos son bastante parecidos en 4 de los modelos y sólo hay una diferencia notable en el modelo que utiliza las tablas del lakehouse con V-Order, que es el más lento. Este resultado me ha sorprendido porque esperaba que el V-Order ayudara en la transcodificación del formato Parquet a VertiPaq, pero al parecer no ha ocurrido así. Es algo que hay que analizar más a fondo y puede que tenga que ver con el tamaño de los archivos Parquet y de los grupos de filas dentro de estos.
El comportamiento del modelo semántico que utiliza los datos del warehouse fragmentado es similar al resto y esto se debe a la optimización automática que expliqué antes.
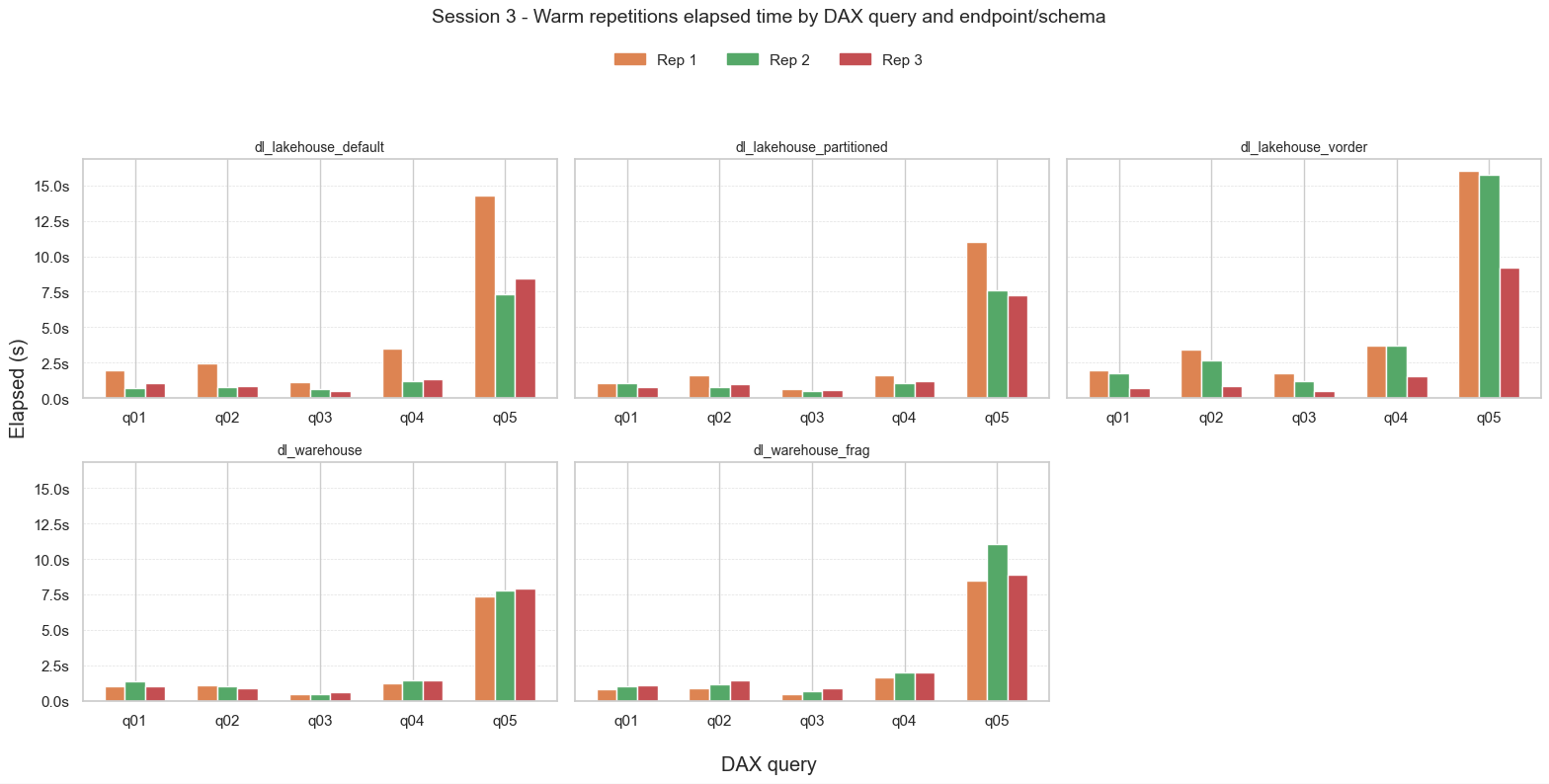
👇 Para finalizar muestro el tiempo de las 3 ejecuciones en caliente para cada una de las 5 consultas DAX en los 5 modelos semánticos.
Me llama un poco la atención que en los tres escenarios del lakehouse (gráficos de arriba) se aprecia que para cada consulta, con cada repetición mejora el rendimiento. Sin embargo, en los dos escenarios del warehouse (gráficos de abajo) casi que ocurre lo contrario.
En el caso del lakehouse con V-Order (tercer gráfico de arriba) hay una mejora apreciable en la tercera repetición.
Como ves, este tema todavía da para mucho. Ojalá te anime a hacer tus propias pruebas y a contribuir al repositorio.