Comparación de rendimiento entre el punto de conexión SQL del lakehouse y el warehouse
El punto de conexión de análisis de SQL de un lakehouse utiliza el mismo motor de consultas T-SQL que el warehouse y en principio deberían tener el mismo rendimiento. Pero este rendimiento se puede ver afectado por la manera en que estén organizados los datos en las tablas Delta.
En un lakehouse tenemos que encargarnos de gestionar la optimización de las tablas Delta, mientras que en un warehouse es Fabric quien se encarga de la gestión.
En este post describo mi primer intento de comparar el rendimiento de consultas T-SQL entre un lakehouse y un warehouse utilizando algunos de los datos y las consultas definidos en el estándar TPC-DS.
He contado con la valiosa ayuda de GitHub Copilot CLI utilizando principalmente el modelo Opus 4.6 de Claude, por lo que también comento el flujo de trabajo que he utilizado.
Todo el código, los datos y las instrucciones las he compartido en el repositorio en GitHub https://github.com/dataxbi/fablab-sql-endpoint
Preparación de los datos
Se ha utilizado un subconjunto de las tablas de TPC-DS con el factor de escala SF100, que determina el volumen de los datos (SF100 ocuparía unos 100 GB si se usan todas las tablas).
A continuación se listan las tablas y la cantidad de filas que contienen.
| Tabla | Tipo | Descripción | Filas (SF100) |
|---|---|---|---|
store_sales |
Hecho | Transacciones de ventas en tienda | 287,997,099 |
customer |
Dimensión | Clientes | 2,000,000 |
customer_demographics |
Dimensión | Segmentación demográfica de clientes | 1,920,800 |
item |
Dimensión | Catálogo de productos | 204,000 |
date_dim |
Dimensión | Calendario (dimensión temporal) | 73,049 |
household_demographics |
Dimensión | Demografía del hogar | 7,200 |
promotion |
Dimensión | Campañas y promociones | 1,000 |
store |
Dimensión | Tiendas físicas | 402 |
Estos datos se han cargado como tablas Delta en un lakehouse y en un warehouse.
En el lakehouse se han creado tres esquemas y en cada uno se han creado las 8 tablas anteriores, pero con configuraciones diferentes:
- default: Sin ninguna configuración adicional
- partitioned: Se ha particionado la tabla de hechos por una columna de fecha
- vorder: Se ha aplicado V-Order a todas las tablas
En todos los casos sí se ha hecho OPTIMIZE sobre las tablas Delta, para eliminar el problema de los ficheros pequeños.
En el warehouse se ha cargado una sola vez cada tabla y no se ha aplicado ninguna configuración adicional.
Por lo que en total hay 4 escenarios para hacer pruebas: 3 con el lakehouse y 1 con el warehouse.
Consultas T-SQL
Se prepararon 5 consultas T-SQL, inspiradas en algunas de las consultas de TPC-DS
Q1 — Agregación simple
- Inspiración TPC-DS: Q29
- Descripción: Suma de ventas y conteo de transacciones agrupados por tienda y mes
- Operaciones:
SUM,COUNT,GROUP BY,ORDER BY - Tablas:
store_sales,date_dim,store - Código: https://github.com/dataxbi/fablab-sql-endpoint/blob/main/sql/q01_simple_agg.sql
Q2 — Join grande (star schema)
- Inspiración TPC-DS: Q19
- Descripción: Ventas totales por producto, marca y clase de tienda, con join a cuatro dimensiones
- Operaciones:
JOIN× 4,GROUP BY,ORDER BY,LIMIT - Tablas:
store_sales,date_dim,item,store,customer - Código: https://github.com/dataxbi/fablab-sql-endpoint/blob/main/sql/q02_large_join.sql
Q3 — Top N con filtros selectivos
- Inspiración TPC-DS: Q6 / Q42
- Descripción: Top 10 artículos por ingresos en una categoría y período específicos
- Operaciones:
WHERE(filtros selectivos en fecha y categoría),ORDER BY,LIMIT - Tablas:
store_sales,date_dim,item - Código: https://github.com/dataxbi/fablab-sql-endpoint/blob/main/sql/q03_top_n_selective.sql
Q4 — Query compleja tipo TPC-DS real
- Inspiración TPC-DS: Q72 / Q14
- Descripción: Análisis de inventario con CTEs, subconsultas correlacionadas y múltiples uniones
- Operaciones: CTEs (
WITH), subqueries,JOIN× 5+, predicados complejos - Tablas:
store_sales,date_dim,item,promotion,household_demographics,customer_demographics - Código: https://github.com/dataxbi/fablab-sql-endpoint/blob/main/sql/q04_complex_tpcds.sql
Q5 — Función ventana analítica
- Inspiración TPC-DS: Q35 / Q86
- Descripción: Ranking de clientes por gasto total usando funciones de ventana
- Operaciones:
RANK(),ROW_NUMBER(),PARTITION BY,ORDER BY - Tablas:
store_sales,customer,date_dim - Código: https://github.com/dataxbi/fablab-sql-endpoint/blob/main/sql/q05_window_function.sql
En el repositorio de GitHub se puede revisar el código de estas consultas.
Pruebas realizadas
Se ha creado un script que se ejecuta en mi ordenador y que utiliza el driver ODBC de SQL Server para conectarse al warehouse y al punto de conexión SQL del lakehouse y lanzar las consultas T-SQL.
Cada una de las 5 consultas se ejecuta en los 4 escenarios comentados antes: lakehouse_default, lakehouse_partitioned, lakehouse_vorder y warehouse.
El lakehouse y el warehouse están en un área de trabajo con una capacidad Fabric F64 de pago.
Primero se ha hecho una ejecución en frío, para lo cual el script se asegura de pausar la capacidad y seguidamente iniciarla y una vez lista, ejecutar las 5 consultas T-SQL en los 4 escenarios, para un total de 20 ejecuciones.
Luego se hacen 3 ejecuciones en caliente de cada una de las 5 consultas T-SQL en los 4 escenarios, para un total de 60 ejecuciones.
Al terminar, el script pausa la capacidad, que los CUs no los regalan. 😁
Los resultados de estas pruebas se guardan en un fichero JSON y otro CSV para poder analizarlos.
Resultados
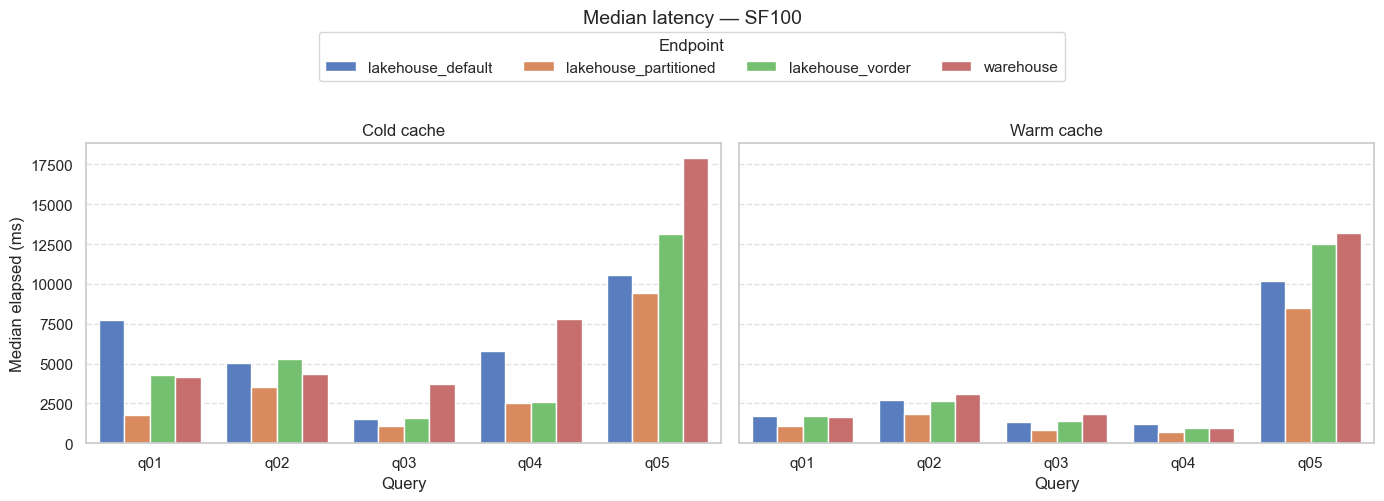
Llegamos al fin a los resultados, que aconsejo tomarlos con cautela al ser un primer intento. Mi intención es ir mejorándolo en futuras iteraciones.
En el gráfico se muestran los resultados de las pruebas en frío a la izquierda y las pruebas en caliente a la derecha. El eje Y es el tiempo que han demorado las consultas T-SQL, por lo que un menor valor indica un mejor resultado. En las pruebas en caliente se usa la mediana de las 3 repeticiones que se hacen de cada consulta T-SQL.
Observando los gráficos se pueden sacar varias conclusiones:
- Las ejecuciones en caliente son más rápidas que las iniciales, como era de esperar.
- En las tablas del lakehouse que no tienen particionado ni V-Order las consultas fueron más lentas, en general.
- El particionado por fecha que se hizo en la tabla de hechos tuvo gran influencia en el rendimiento.
- Las tablas con V-Order no siempre obtuvieron buenos resultados.
- Las consultas en el warehouse están entre las más lentas.
Este último punto me llama la atención, porque esperaba que las consultas del warehouse fueran más rápidas, debido a la gestión automática de las tablas Delta que hace Fabric en el warehouse. Esto merece más investigación 🤔.
Trabajo con GitHub Copilot CLI
Para desarrollar estas pruebas he utilizado GitHub Copilot CLI con el plan Pro+ de GitHub Copilot. Con este plan hay acceso a varios modelos, y la mayor parte del tiempo he utilizado Claude Sonnet 4.6.
Me puse como objetivo que Copilot escribiera todo el código e hiciera las pruebas y también que se encargara de gestionar los elementos de Fabric y hacer los commits de Git.
Mi papel ha consistido fundamentalmente en planear las especificaciones con la ayuda de Copilot, revisarlas y aprobarlas, y chequear los resultados cuando Copilot termina el trabajo planeado. Y repetir el proceso hasta alcanzar unos resultados razonables.
Todo el código, los datos y las instrucciones las he compartido en el repositorio en GitHub https://github.com/dataxbi/fablab-sql-endpoint
Antes de comenzar a planear he:
- Instalado Skills for Fabric
- Creado un área de trabajo en Fabric
- Creado una capacidad Fabric F64 de pago por uso y la he puesto en pausa
Para comenzar he puesto a GitHub Copilot CLI en modo plan (Mayúscula + TAB) y le he comentado lo que quería hacer. Fue él quien me sugirió utilizar TPC-DS y me propuso las 5 consultas T-SQL, inspiradas en consultas de TPC-DS.
También me sugirió generar los datos utilizando la aplicación DSGEN, de TPC-DS, y utilizar los factores de escala SF10, SF500 y SF1000. Cada uno de estos SF implica un conjunto de datos de mayor tamaño, las mismas tablas, pero con más filas. El SF10 se usaría solo para probar que todo funcione bien y las pruebas se harían con los SF más grandes.
Luego de varios intercambios en el modo plan acordamos dividir el proyecto en varias etapas:
- Generar los datos de TPC-DS localmente, en formato CSV
- Crear el lakehouse y el warehouse en Fabric
- Subir los ficheros CSV al lakehouse
- Cargar los datos en las tablas del lakehouse (un esquema por cada escenario) y el warehouse
- Ejecutar las pruebas desde mi ordenador
- Visualizar el resultado de las pruebas
Una vez definida la primera versión del plan, le pedí generar un fichero con el nombre especificaciones.md, con los detalles del plan, en español, y que no hiciera nada más hasta que yo lo revisara y lo aprobara.
Después de hacer algunos ajustes en la especificación, continué en el modo plan para añadirle algunas cuestiones técnicas:
- Que para cada paso del plan genere scripts en Python o PowerShell
- Que instale un entorno local de Python y mantenga el registro de bibliotecas que se instalen
- Que cuando yo apruebe un plan, actualice la especificación
- Que a partir de la especificación genere un fichero copilot-instructions.md en inglés. (Esto no tengo claro que sea necesario)
- Que en los commits de la especificación yo sea el autor y Copilot el coauthor, pero que en los commits del código el autor sea Copilot.
Primero hicimos todo el proceso con SF10 y fuimos corrigiendo varios detalles por el camino. Pero al tratar de generar SF500 me doy cuenta de que ocuparía alrededor de 500 GB y que tardaría bastante tiempo en la ingesta.
Por lo tanto, decidí hacer las pruebas con solo SF100. No obstante, surgió un pequeño reto porque los CSV más grandes tardaban demasiado en subirse a Fabric. La solución fue dividirlos en ficheros más pequeños y comprimirlos antes de subirlos.
Otro ejemplo de cambios en la planificación inicial, es que quería probar 4 escenarios con el lakehouse: default, partitioned, vorder y zorder, pero este último lo tuve que desechar en las pruebas iniciales porque consumía mucho tiempo aplicarle Z Order a las tablas más grandes.
Cada vez que había un cambio en el plan, se hacía commit, por lo que si revisas el historial del repositorio verás estos cambios que he comentado y muchos más.
Bueno, ojalá te haya motivado a hacer tus propias pruebas y a contribuir con el repositorio.