Comparación de rendimiento entre el punto de conexión SQL del lakehouse y el warehouse - Fragmentación
En este post comparo la influencia de la fragmentación de las tablas Delta en el rendimiento de las consultas T-SQL en un lakehouse vs. un warehouse.
Se han utilizado los mismos datos que expliqué en el post anterior y que son un subconjunto de las tablas de TPC-DS, con el factor de escala SF100.
| Tabla | Tipo | Descripción | Filas (SF100) |
|---|---|---|---|
store_sales |
Hecho | Transacciones de ventas en tienda | 287,997,099 |
customer |
Dimensión | Clientes | 2,000,000 |
customer_demographics |
Dimensión | Segmentación demográfica de clientes | 1,920,800 |
item |
Dimensión | Catálogo de productos | 204,000 |
date_dim |
Dimensión | Calendario (dimensión temporal) | 73,049 |
household_demographics |
Dimensión | Demografía del hogar | 7,200 |
promotion |
Dimensión | Campañas y promociones | 1,000 |
store |
Dimensión | Tiendas físicas | 402 |
También he contado con la valiosa ayuda de GitHub Copilot CLI, y en el post anterior explico el flujo de trabajo que he seguido.
Todo el código, los datos y las instrucciones las puedes consultar en el repositorio en GitHub https://github.com/dataxbi/fablab-sql-endpoint.
Preparación de los datos
Esta vez se ha creado un nuevo esquema en el lakehouse y otro en el warehouse, ambos con el mismo nombre: benchmark_frag.
Las tablas de dimensiones se han copiado desde el esquema benchmark_default, explicado en el post anterior, usando consultas CREATE TABLE AS SELECT (CTAS). En el lakehouse se ha utilizado Spark SQL y en el warehouse T-SQL.
La tabla de hechos store_sales es la que se ha fragmentado en archivos Parquet muy pequeños, de 10.000 filas cada uno. Por lo que para alcanzar las casi 288 millones de filas se han creado unos 29.000 archivos Parquet.
⚠️ Este proceso de fragmentación lo estoy haciendo para estas pruebas, pero en un proyecto real por lo general se hace todo lo contrario. 😉
El proceso de fragmentación fue diferente en cada elemento de almacenamiento.
En el lakehouse se partió de la tabla store_sales del esquema benchmark_default y se copiaron sus datos en una tabla con el mismo nombre pero en el nuevo esquema benchmark_frag, con sobrescritura y lo más importante, con la opción maxRecordsPerFile.
MAX_RECORDS_PER_FILE = 10000
spark.table("benchmark_default.store_sales")
.write
.format("delta")
.mode("overwrite")
.option("overwriteSchema", "true")
.option("maxRecordsPerFile", str(MAX_RECORDS_PER_FILE))
.saveAsTable("benchmark_frag.store_sales")
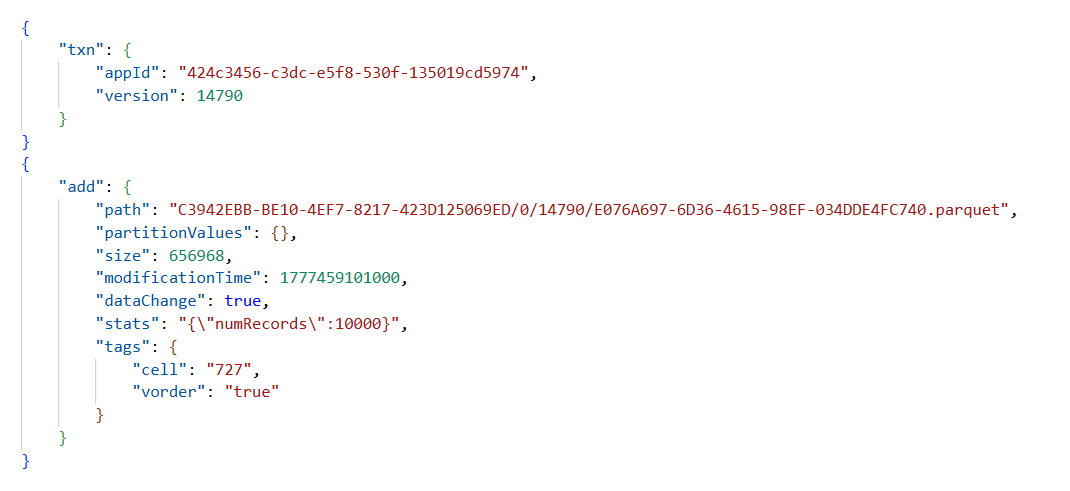
La imagen muestra un fragmento del delta_log de la tabla Delta creada en el lakehouse, donde se puede apreciar que en una misma transacción se han creado todos los archivos Parquet y que cada uno contiene 10.000 filas.

En el warehouse se utilizó una estrategia diferente porque en T-SQL no hay una opción equivalente a maxRecordsPerFile.
Se partió del archivo CSV con los datos de la tabla store_sale, cuya generación se explicó en el post anterior. Este se dividió en archivos CSV con 10.000 filas cada uno, obteniendo casi 29.000 archivos CSV. Los archivos se compactaron, se subieron a una carpeta del lakehouse y se descompactaron.
Se creó la tabla store_sale en el esquema benchmark_frag del warehouse.
Se utilizó el comando T-SQL COPY INTO para insertar los datos desde los archivos CSV en el lakehouse hacia la tabla en el warehouse.
COPY INTO benchmark_frag.store_sales
FROM <FILE_URL>
WITH (FILE_TYPE = 'CSV', FIELDTERMINATOR = '|')
Para optimizar la copia, se creó un script que utiliza el driver ODBC de SQL Server para conectarse al warehouse desde mi ordenador, y que implementa un mecanismo para ejecutar varias consultas COPY INTO en paralelo.
Las inserciones no se han hecho dentro de una misma transacción por lo que en la tabla Delta se ha creado un delta_log por cada archivo Parquet que se ha creado. En la figura se ve el contenido de uno de estos delta_log.
Pruebas realizadas
Para medir el rendimiento se han utilizado las mismas 5 consultas T-SQL que en el post anterior, inspiradas en consultas del TCP-DS:
-
Q1 — Agregación simple: https://github.com/dataxbi/fablab-sql-endpoint/blob/main/sql/q01_simple_agg.sql
-
Q2 — Join grande (star schema): https://github.com/dataxbi/fablab-sql-endpoint/blob/main/sql/q02_large_join.sql
-
Q3 — Top N con filtros selectivos: https://github.com/dataxbi/fablab-sql-endpoint/blob/main/sql/q03_top_n_selective.sql
-
Q4 — Query compleja tipo TPC-DS real: https://github.com/dataxbi/fablab-sql-endpoint/blob/main/sql/q04_complex_tpcds.sql
-
Q5 — Función ventana analítica: https://github.com/dataxbi/fablab-sql-endpoint/blob/main/sql/q05_window_function.sql
Se extendió el script explicado en el post anterior, para poder ejecutar estas consultas sobre las tablas de los nuevos esquemas benchmark_frag.
En este caso todas las consultas se hicieron en caliente, sin pausar la capacidad Fabric. Y se utilizó una capacidad Fabric F64 de pruebas.
Se ejecutaron 3 repeticiones de cada consulta en los 6 esquemas: los cuatro que se explicaron en el post anterior, y los los dos nuevos benchmark_frag.
En total se hicieron 90 ejecuciones.
Los resultados de estas pruebas se guardaron en archivos CSV para poder analizarlos.
Resultados
A continuación muestro tres imágenes con los resultados de las pruebas.
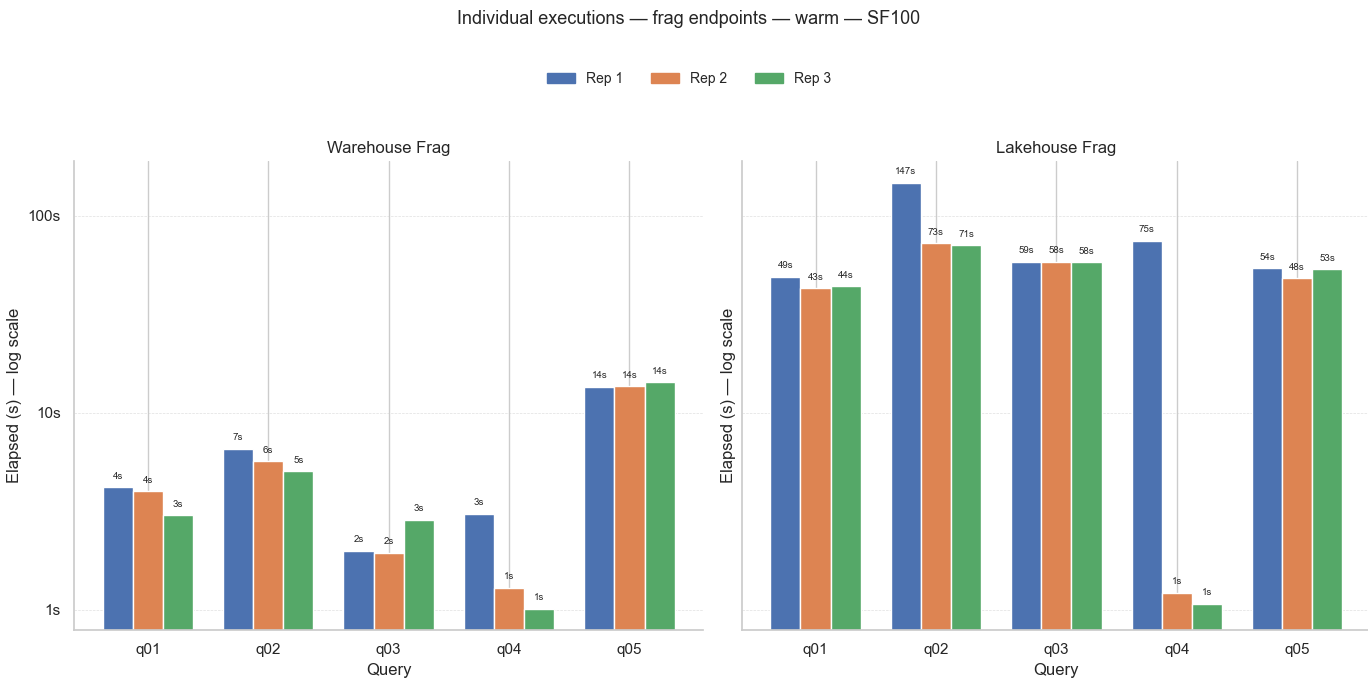
👆La primera imagen contiene dos gráficos de columnas con el tiempo de las 3 ejecuciones de cada consulta sobre las tablas fragmentadas (esquema benchmark_frag) del warehouse (gráfico de la izquierda) y el lakehouse (gráfico de la derecha).
De primeras se aprecia que las consultas del lakehouse tardaron más que las del warehouse. Y si prestamos más atención al eje Y, nos daremos cuenta que la escala es logarítmica, por lo que la diferencia es aún mayor que lo que muestran las columnas. Como referencia, la consulta que más tardó en el warehouse fue de 14 segundos, mientras que la que más tardó en el lakehouse fue de 147 segundos.
También hay que destacar cómo la consulta Q04 va mejorando el rendimiento en cada repetición, y esto sucede en ambos elementos de almacenamiento.
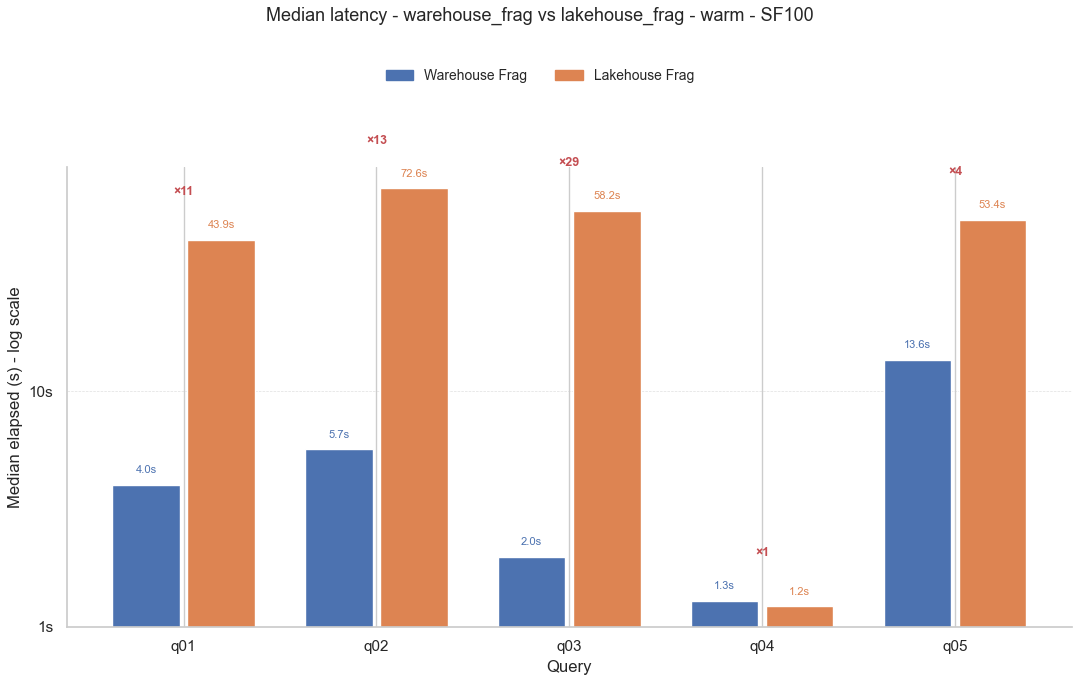
👆 La segunda imagen es un gráfico de columnas, también con escala logarítmica, donde se compara la mediana de las 3 repeticiones de cada consulta en las tablas fragmentadas (esquema benchmark_frag) entre el warehouse (izquierda, azul) y el lakehouse (derecha, naranja). Se aprecia claramente como el warehouse tiene un rendimiento que es varios órdenes de magnitud superior al del lakehouse, llegando a ser hasta 29 veces más rápido (consulta Q03).
La excepción es la consulta Q04 que ya vimos en el primer gráfico que mejora mucho el rendimiento luego de la primera repetición, por lo que al considerar la mediana en este gráfico no hay casi ninguna diferencia entre el lakehouse y el warehouse.
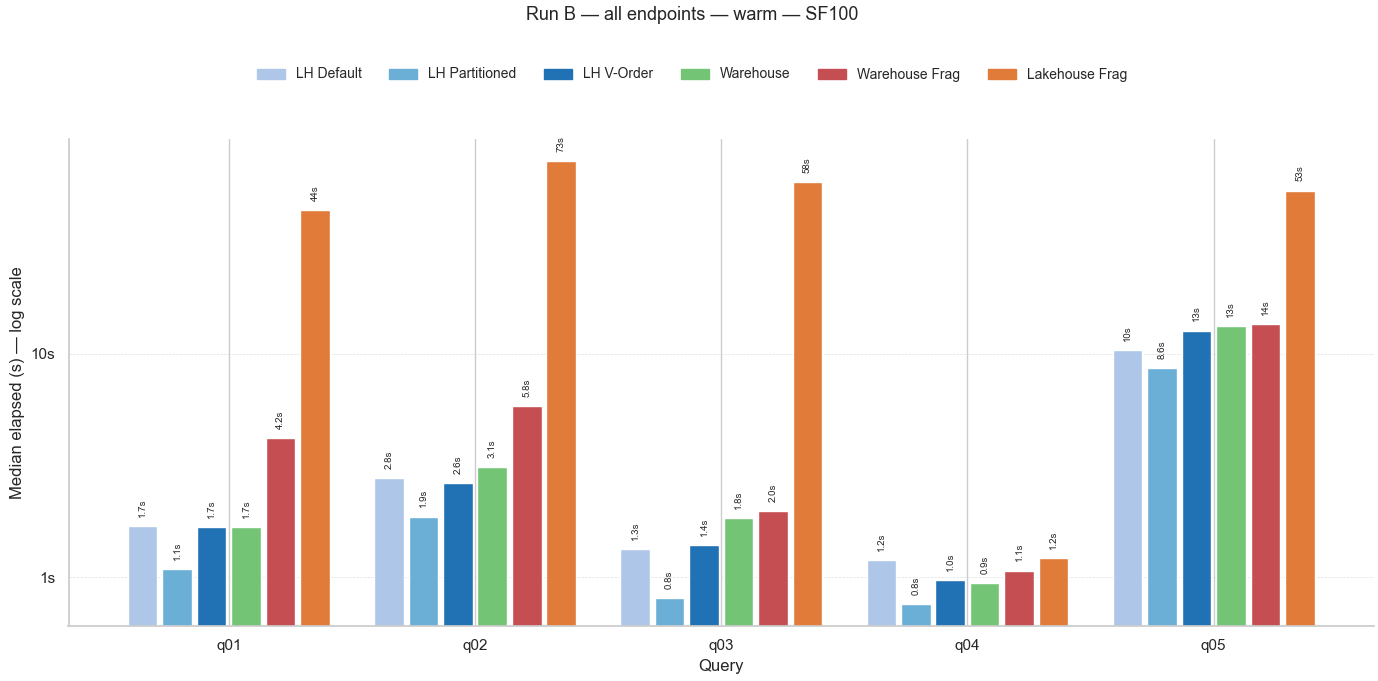
👆 La última imagen es otro gráfico de columnas con escala logarítmica que compara la mediana de las ejecuciones de las 5 consultas en todos los escenarios de este post y del anterior.
Aquí se aprecia claramente que el lakehouse fragmentado (naranja, derecha) es el de peor rendimiento, excepto en la consulta Q04.
Conclusión
La principal conclusión que podemos extraer de estas pruebas es algo bastante conocido: las tablas Delta no rinden bien cuando contienen muchos archivos de datos de pequeño tamaño. Es por esa razón que en un lakehouse debemos encargarnos de su mantenimiento utilizando los comandos OPTIMIZE y VACUUM, junto a otras técnicas.
Por otra parte, aunque un warehouse también utiliza tablas Delta, hay procesos automáticos que se encargan del mantenimiento.
Si quieres profundizar sobre el mantenimiento y optimización de las tablas Delta, te dejo un artículo de la documentación oficial: https://learn.microsoft.com/es-es/fabric/fundamentals/table-maintenance-optimization