Tips para organizar las consultas Power Query - Parte 3
Esta es la tercera entrada del tema de buenas prácticas para la organización de las consultas en el editor de Power Query donde hablaremos de la técnica “Multi-Query Architecture†que explican Ken Puls y Miguel Escobar en su libro Master Your Data Power Query in Excel and Power BI.
Los otros artículos de la serie:
Esta técnica consiste en dividir cada consulta en varias consultas, es decir, añadir capas de consultas adicionales, que permitirán controlar el crecimiento del tamaño y la complejidad de las consultas. La idea es que en lugar de tener una única consulta con todos los pasos del proceso de ETL tengas varias consultas, como mínimo una por cada fase del proceso, es decir, una consulta para la extracción de datos, otra para las transformaciones y otra para el modelo. A estas capas las denominaron Raw Data, Staging y Data Model.
Contenido de cada capa
Capa Raw Data
####
Esta capa se utiliza para extraer los datos del origen. Las consultas de esta capa requieren de unas pocas transformaciones: conexión a la fuente de datos y navegación fundamentalmente. En algunos casos necesitaremos filtrar las filas y columnas que no sean necesarias. El objetivo de esta capa es tener una tabla con todos los registros del conjunto de datos.
En nuestro caso a esta capa la denominaremos Originales y contendrá los datos porque la conexión ya la hemos creado en una consulta separada utilizando la técnica de File Proxy que vimos en la segunda entrada sobre el tema Tips para organizar las consultas Power Query - Parte 2 y a la que hemos llamado Consulta Maestra. Nuestras consultas en esta capa tendrán dos pasos: Origen que es una referencia a la Consulta Maestra y Navegación donde se seleccionan los datos de esa consulta.
Capa Staging
En esta capa se llevarán a cabo la mayor parte de las transformaciones del proceso de ETL, incluyendo la creación de las llaves subrogadas. El paso Origen hace referencia a la consulta de la capa Raw Data correspondiente. Puede requerir la creación de más de una consulta, es decir, si el proceso de transformación es muy complejo o contiene demasiados pasos se puede dividir en varias consultas a su vez.
A esta capa la nombraremos Trasnformadas.
Capa Data Model
En esta capa están las consultas que se cargan en el modelo. El paso origen de la consulta hace referencia a la consulta correspondiente de la capa de Staging y realiza algunas transformaciones finales.
Transformaciones de la capa Data Model
Anexar y/o combinar con otras consultas:
En esta transformación podemos combinar o anexar consultas de la capa staging. Por ejemplo, si hemos creado columnas de llaves subrogadas en la capa de transformación, debemos combinar las tablas de hecho con esas consultas para obtener la nueva clave.
Eliminar columnas:
En las consultas de dimensiones y de hechos que se cargarán en el modelo debemos eliminar las columnas con la clave original y en su lugar utilizaremos las claves sustitutas para relacionar las tablas en el modelo.
Renombrar columnas:
Las columnas claves sustitutas pueden renombrase utilizando el nombre que tenía la clave original una vez que se hayan eliminado en un paso anterior. Este paso es opcional.
Asignar tipo de datos a las columnas:
Es importante que todas las columnas de las tablas que se carguen en el modelo tengan asignado correctamente el tipo de datos, sobre todo en el caso de las columnas que contiene los hechos y sobre las que se realizarán operaciones que dependen del tipo de datos. Debemos evitar asignarle tipos de datos a las columnas antes este momento porque de hacerlo se podrían generar errores si se modifica la estructura original de los datos o se cambia el origen inicial.
A esta capa la llamaremos Modelo.
Agrupar consultas
Como vimos en la primera entrada de esta serie es buena práctica agrupar las consultas en carpetas. En este caso crearemos una carpeta para cada una de las capas: Originales, Transformadas y Modelo. Debajo de la carpeta Modelo añadiremos dos subcarpetas una para las tablas de hechos y otra para las de dimensiones.
En el caso que estemos realizando el ETL con flujos de datos y tengamos una licencia Premium podríamos incluso separar cada capa de consultas en un flujo diferente, un flujo para cada etapa del proceso.
Ejemplo del uso de la técnica
Para mostrar cómo aplicar esta técnica utilizaremos el PBIX que se obtuvo como resultado en la entrada anterior del tema.
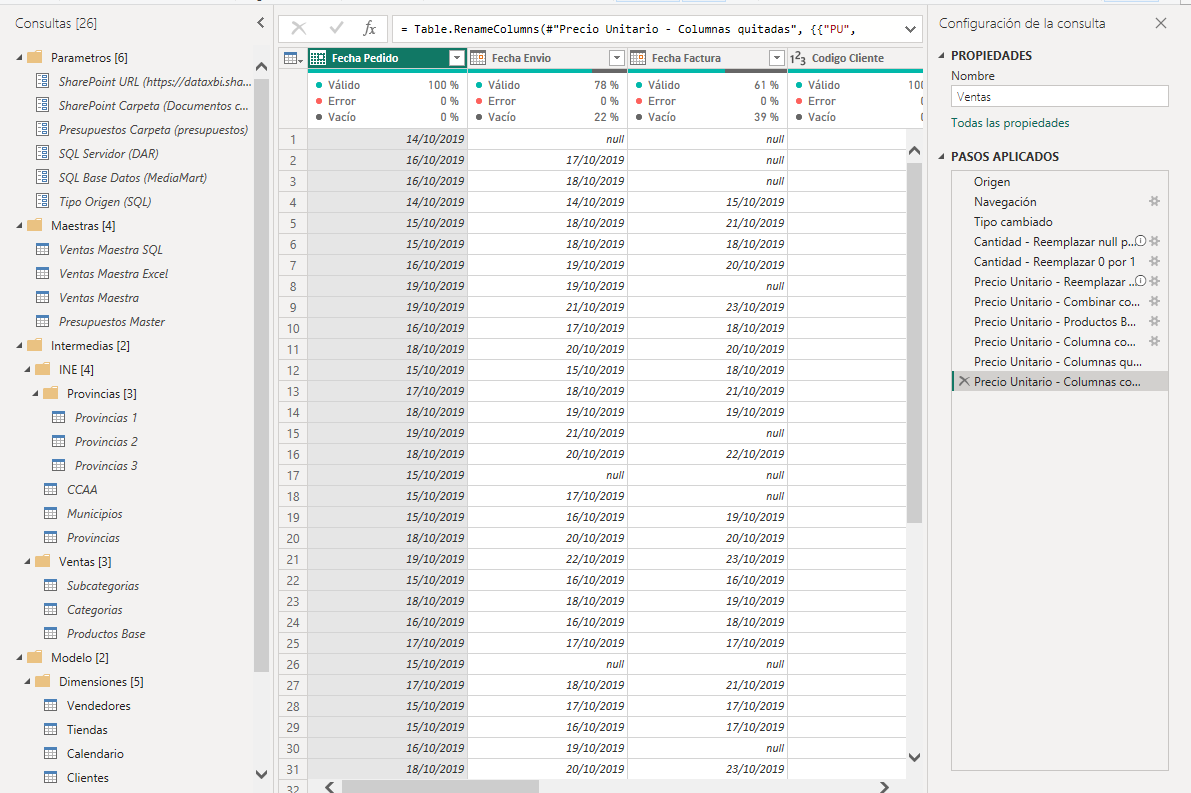
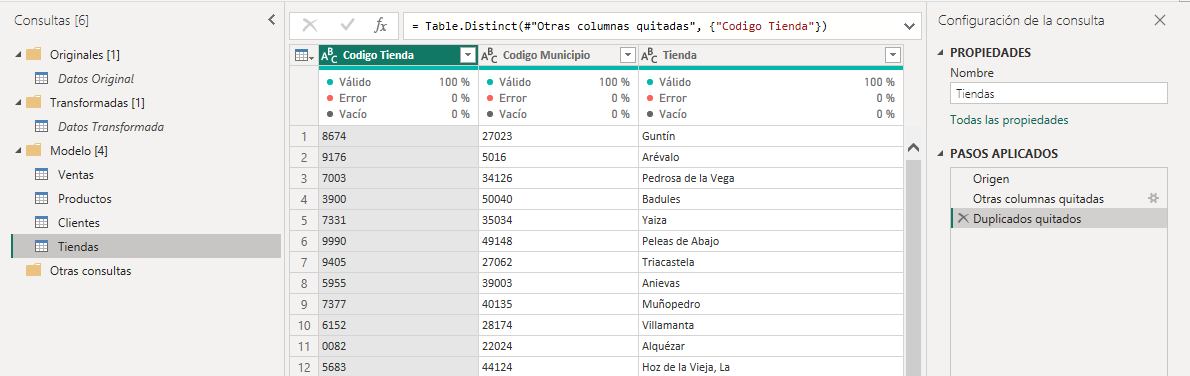
Comenzaremos por analizar la consulta Clientes. Podemos observar que en el paso Origen la consulta hace referencia a la consulta Ventas Maestra y muestra todos los datos de ese origen.
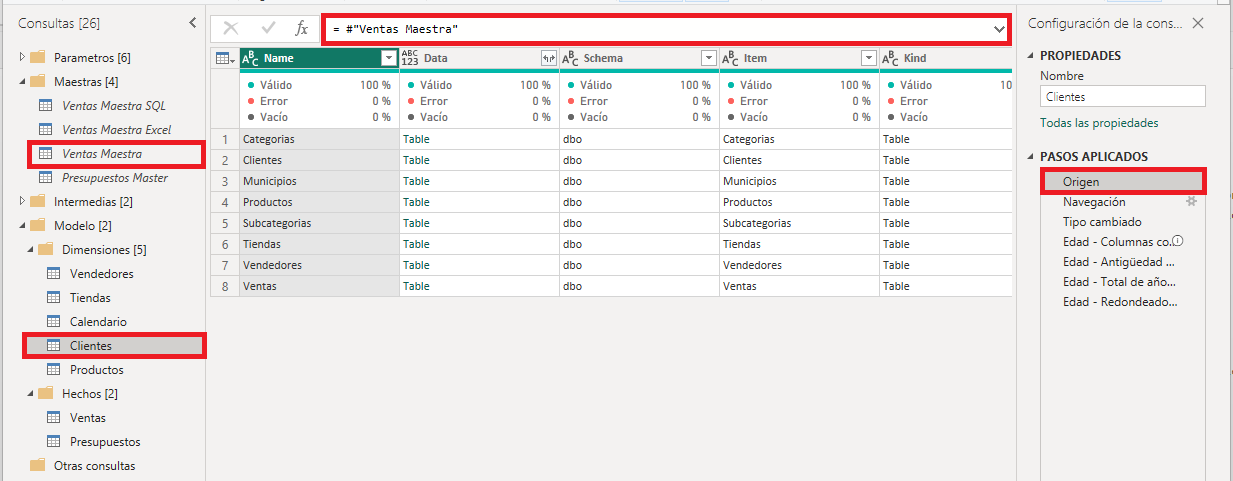
En el paso navegación de esta consulta es donde seleccionamos la tabla Clientes que contiene los datos de los clientes.
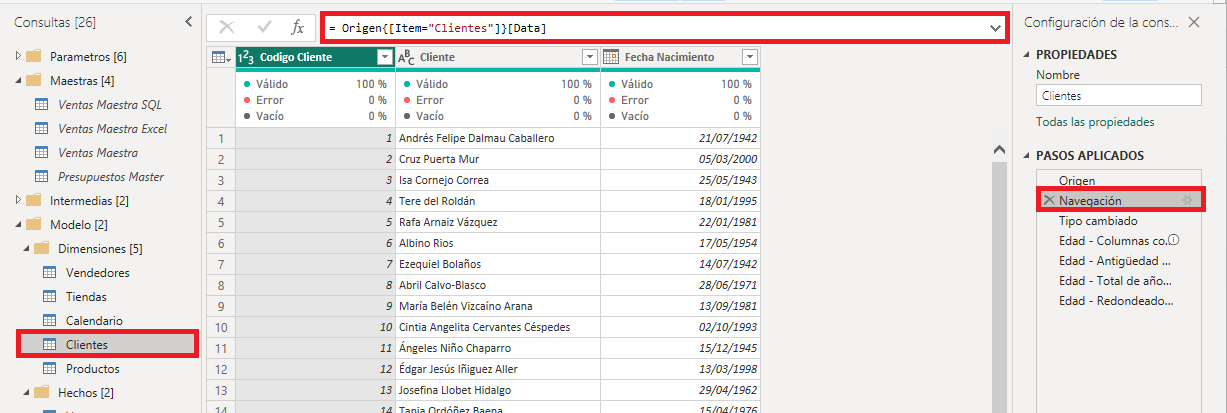
En el Paso 3 de la consulta se asigna el tipo de datos correspondiente a cada columna. En este punto podemos dividir la consulta en dos. La primera, Clientes Original que contendrá los dos primeros pasos y la segunda que contendrá el resto de los pasos. Para ello utilizaremos la opción Extraer anteriores del menú contextual del paso Tipo cambiado.
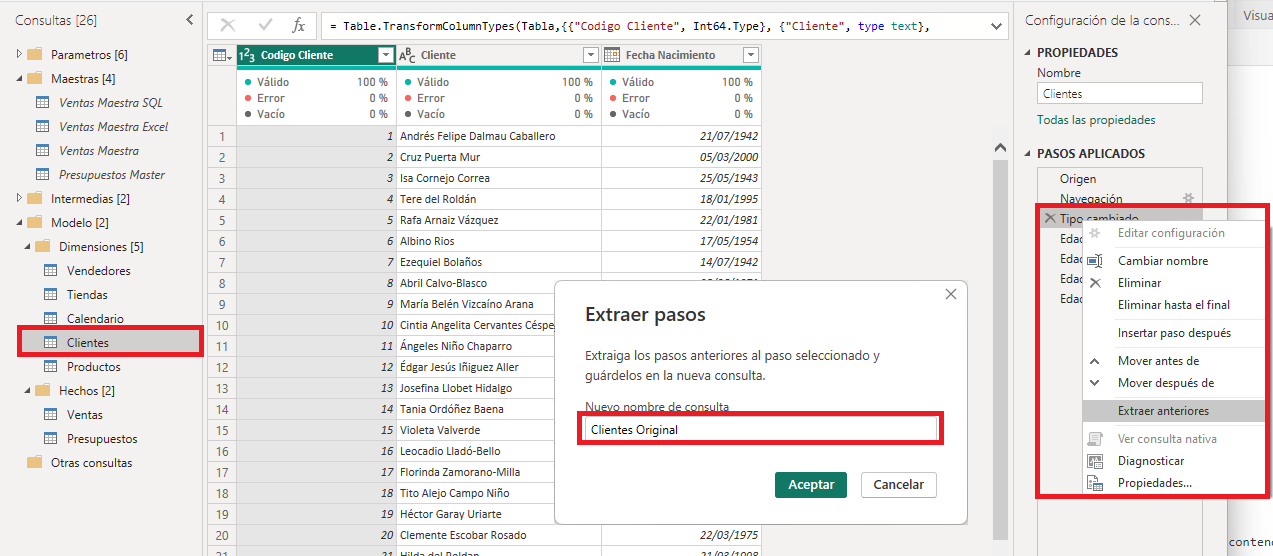
En el cuadro de dialogo Extraer pasos especificamos el nombre de la nueva consulta, Clientes Original.
Como resultado nos quedan dos consultas con los datos de los clientes, Clientes Original, que contiene dos pasos: Origen, que hace referencia a la consulta Ventas Maestra y Navegación donde escogemos la tabla Clientes y la consulta Clientes que en el paso Origen hace referencia a Clientes Original y contiene el resto de las transformaciones. A la consulta Cliente Original le deshabilitamos la carga y la guardamos en la carpeta Originales que agrupará todas las consultas de esta capa.
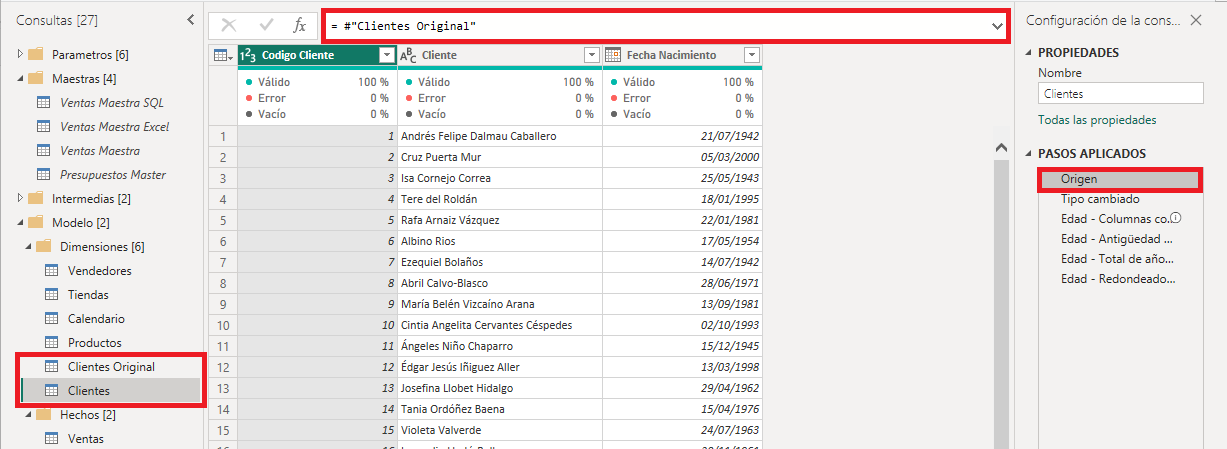
A continuación realizaremos varias transformaciones sobre la consulta Clientes. Primero eliminaremos el paso Tipo cambiado, luego añadiremos una columna índice y la llamaremos Cliente ID, esta columna será la clave sustituta de esta tabla. Cambiaremos el nombre de la consulta por Clientes Transformada y la guardaremos en la carpeta Transformadas, que agrupará a las consultas de esta capa. Por último, deshabilitaremos la carga de esta consulta. El resultado lo puedes ver en la siguiente imagen.
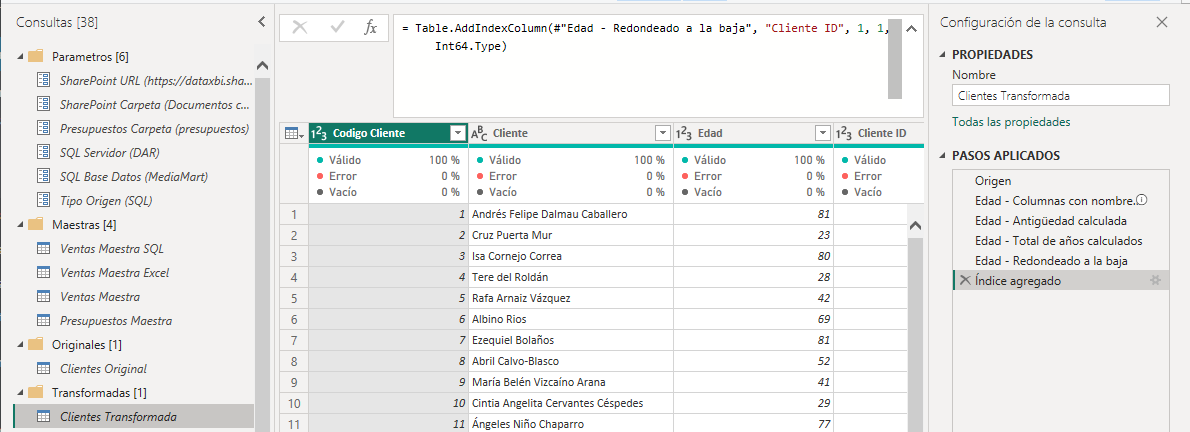
Crearemos ahora la consulta Clientes que se cargará en el modelo. Esta consulta será una referencia a la consulta Clientes Transformada.
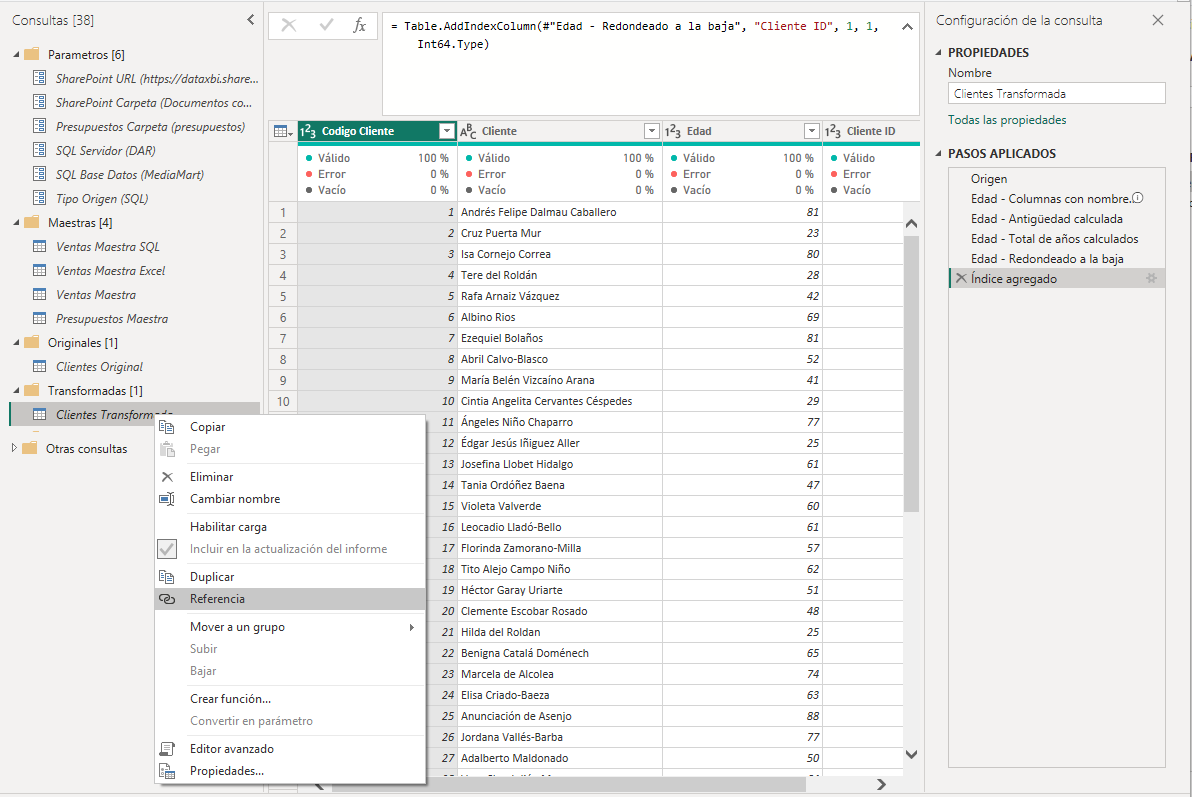
Además del paso Origen que será una referencia a la consulta Clientes Transformada añadiremos tres nuevas transformaciones: Eliminar el campo Codigo Cliente, que es la clave del negocio, renombrar a la clave sustituta con el nombre de la clave del negocio (este paso es opcional) y asignar el tipo de dato correspondiente a cada columna.
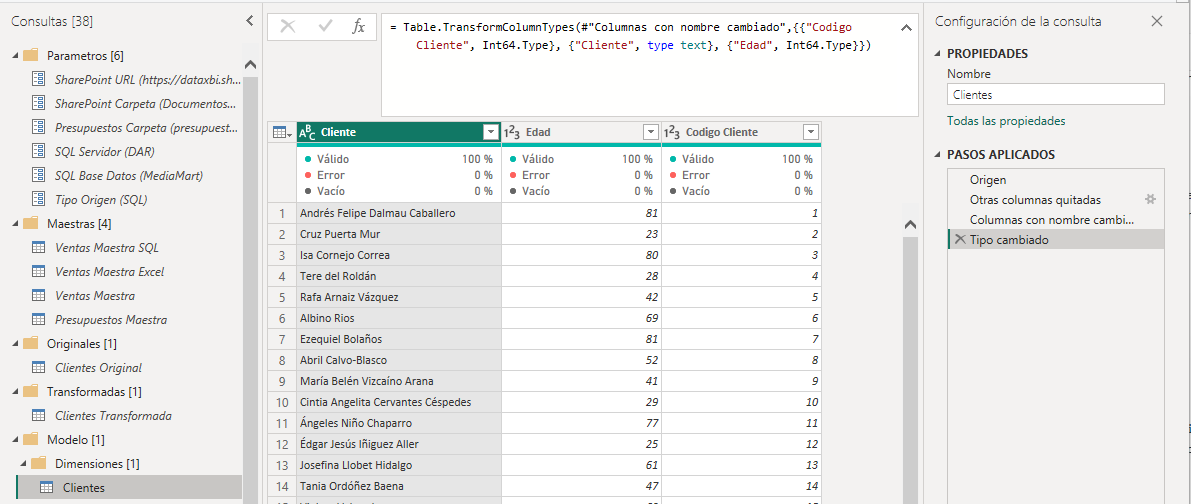
Esta consulta la guardaremos en la carpeta Modelo, correspondiente a la capa del modelo, dentro de la subcarpeta Dimensiones, que habíamos creado previamente.
La siguiente imagen nos muestra el proceso de ETL de la consulta Clientes dividido en cada una de las consultas y la dependencia entre ellas.
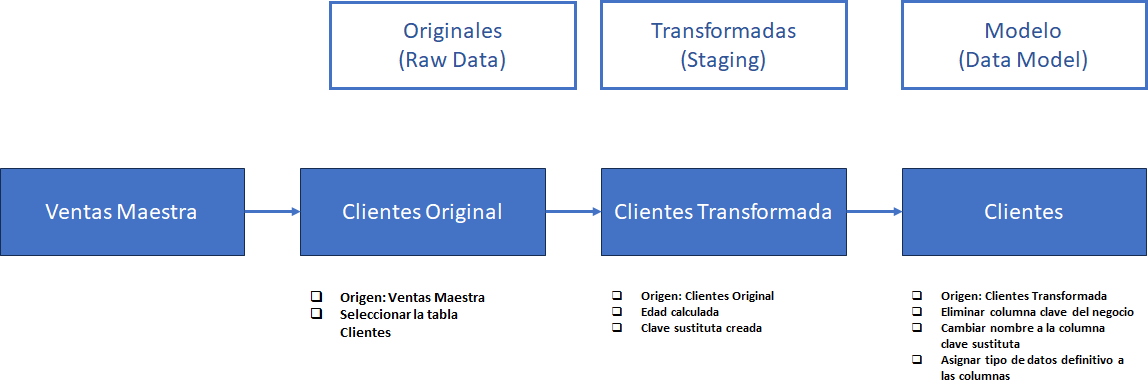
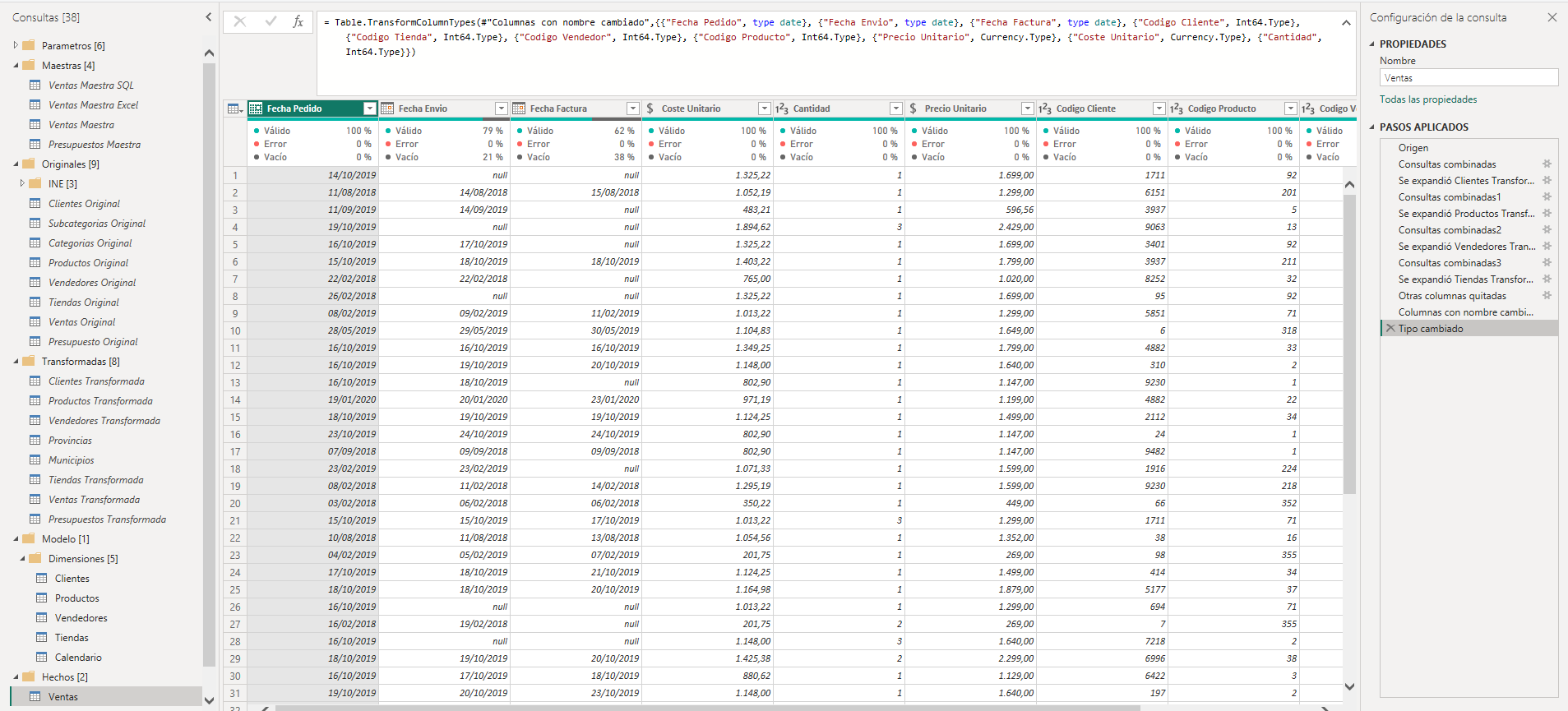
Vamos a ver otro ejemplo en este caso escogeremos la tabla de hechos Ventas.
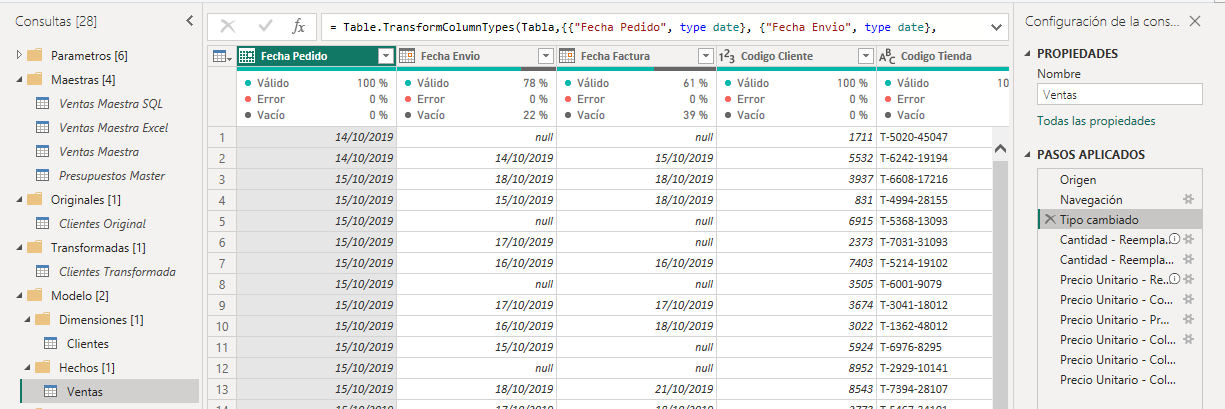
Los tres primeros pasos de la consulta se ven exactamente iguales a los de la consulta Cliente y vamos a extraer los dos primeros pasos en una nueva consulta como hicimos en Cliente.
La consulta Ventas Original contendrá solamente dos pasos Origen y Navegación, igual que Clientes Original, se le deshabilitará la carga y se guardará en la carpeta Originales.
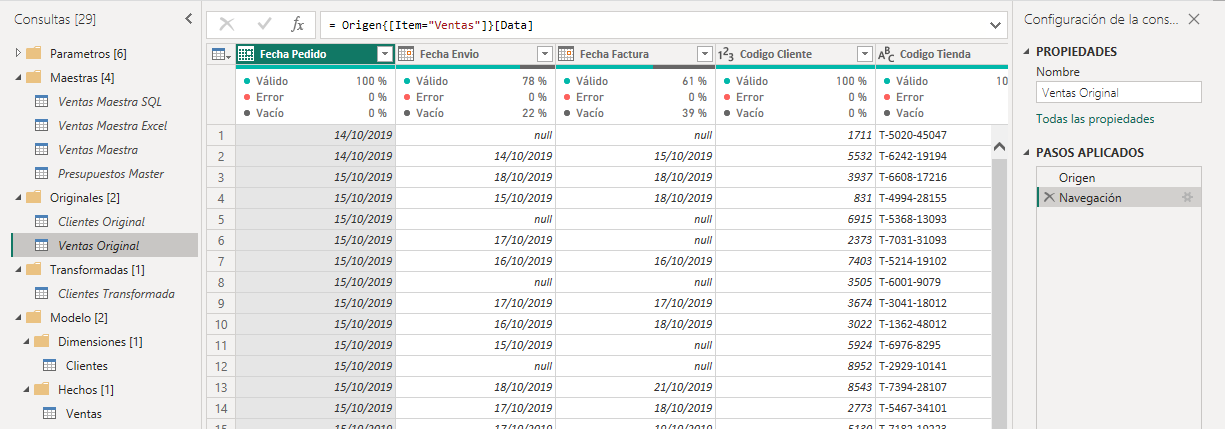
La consulta Ventas contiene el grueso de las transformaciones. La seleccionamos y desplazamos el paso Tipo cambiado al final y de nuevo extraeremos los pasos anteriores a este en una nueva consulta a la que llamaremos Ventas transformada, le deshabilitamos la carga y la guardaremos en la carpeta Transformadas.
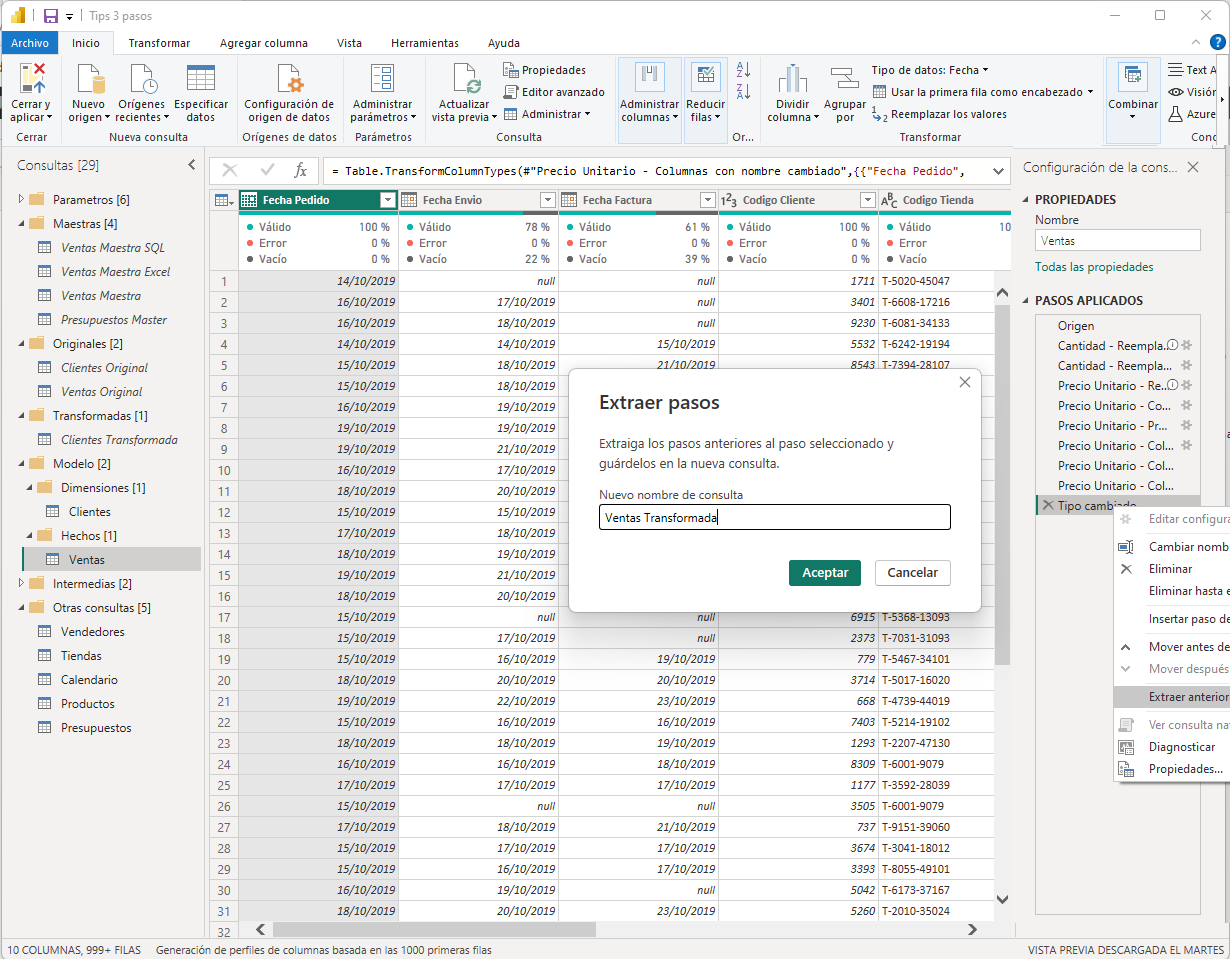
La consulta Ventas contiene ahora solo dos pasos, el paso Origen que hace referencia a Ventas Transformada y el paso Tipo cambiado donde se le asigna el tipo de datos correspondiente a cada columna.
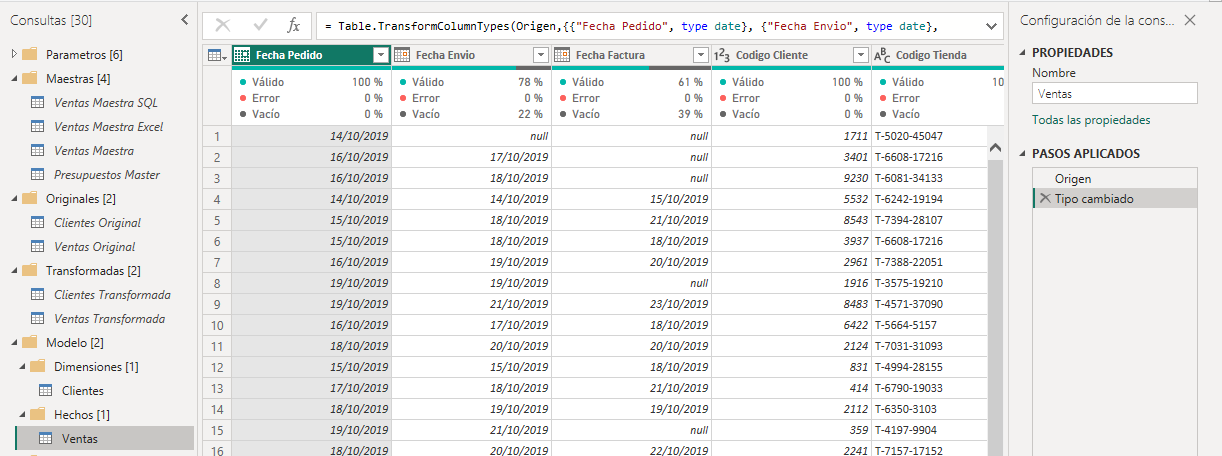
A continuación, realizaremos algunas transformaciones a la consulta Ventas. Lo primero será combinar con la consulta Clientes Transformada para traer la clave sustituta creada en esta consulta. Estas transformaciones debemos realizarla con todas las consultas de dimensiones a las que se le haya creado una clave sustituta. Una vez que combinadas con todas las tablas de dimensiones lo próximo será eliminar las claves del negocio de cada dimensión. El siguiente paso, opcional, es renombrar las claves sustitutas con el nombre de su clave de negocio. Por último movemos el paso Tipo cambiado al final y comprobamos que se ha asignado el tipo correcto a cada columna. En este momento estaremos listos para cargar la tabla Ventas en el modelo.
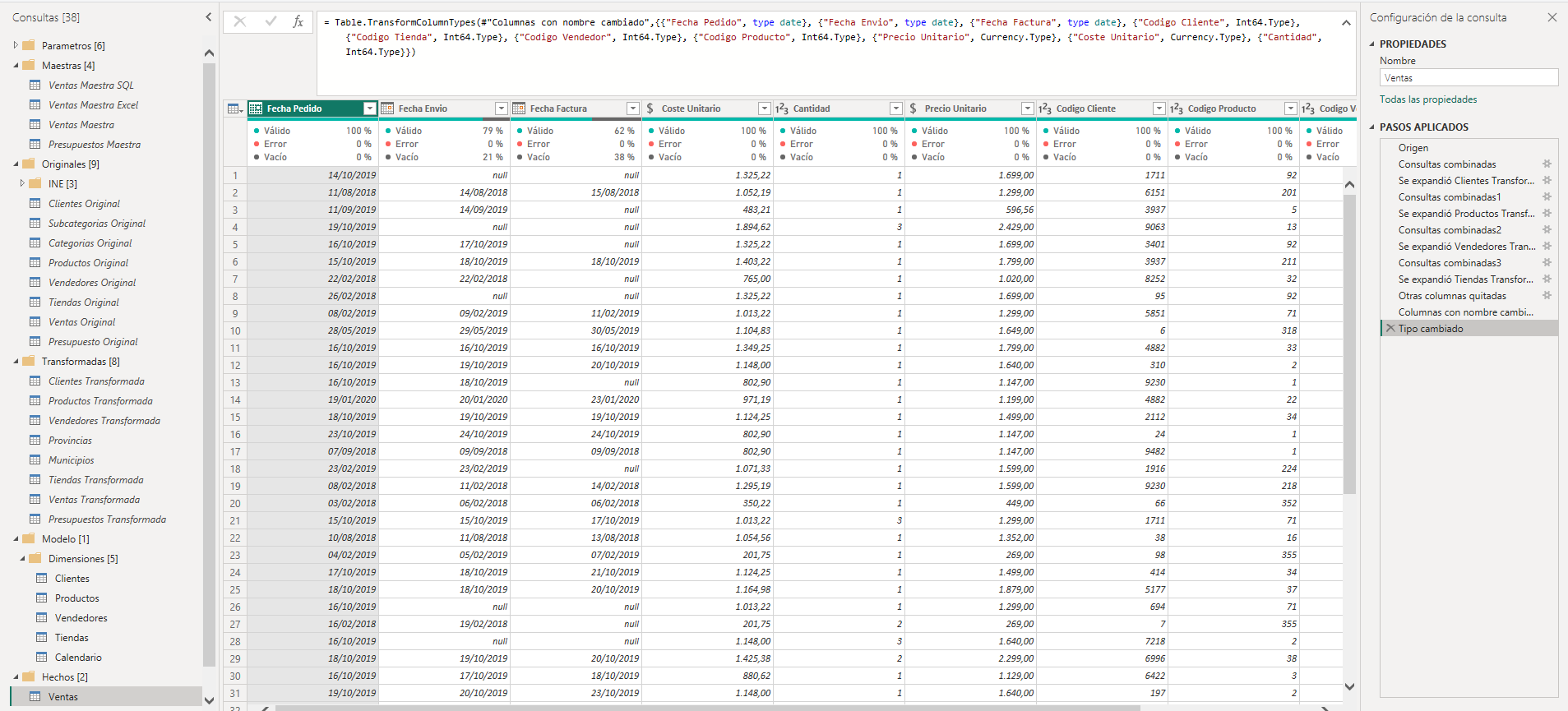
La siguiente imagen nos muestra la dependencia entre las consultas de ventas en cada una de las capas y las transformaciones realizadas en cada capa.
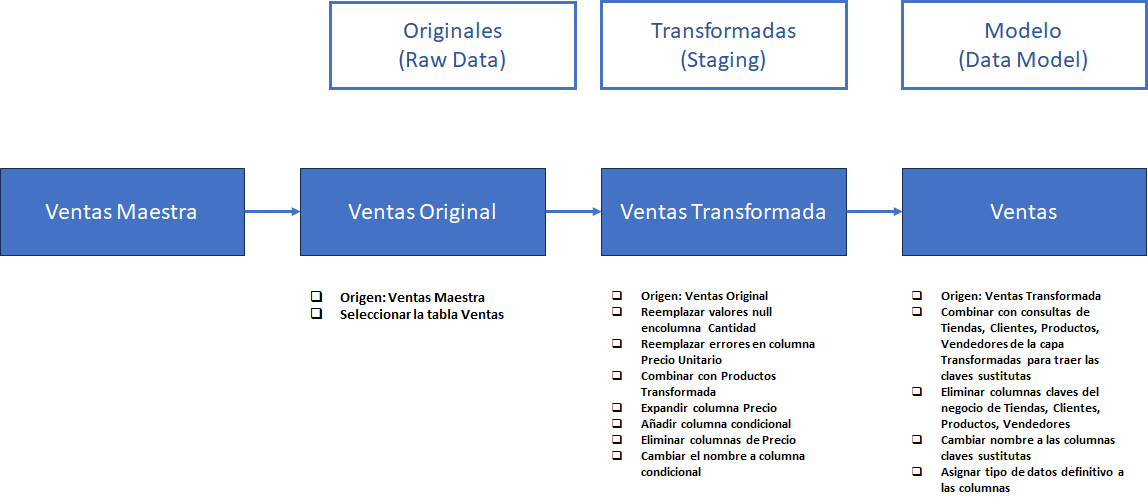
Debajo, en la imagen, podemos ver como han quedado organizadas las consultas en el Editor de Power Query.
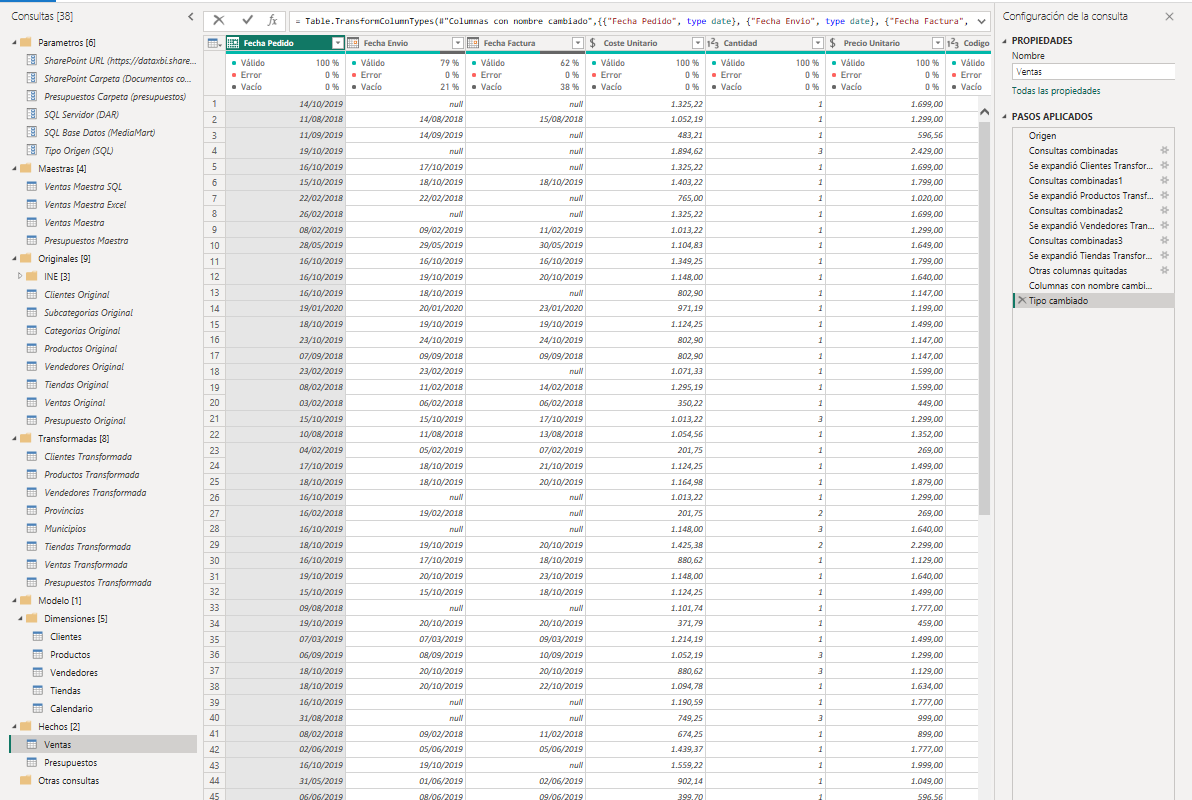
Como se puede ver el número de consultas ha crecido pero podemos identificar claramente el contenido de cada consulta y donde realizar cada tipo de transformación.
Plegado de consultas
En el caso en que el origen de datos soporte plegado de consultas, al dividir la consulta en varias, el plegado se sigue manteniendo a menos que una transformación lo rompa.
En el ejemplo que estamos estudiando uno de los orígenes es SQL Server. Si seleccionamos la consulta Ventas de la capa Modelo y nos paramos en el paso Navegación podemos ver que el plegado de consultas no se ha roto y podemos ver la consulta TSQL que se genera:
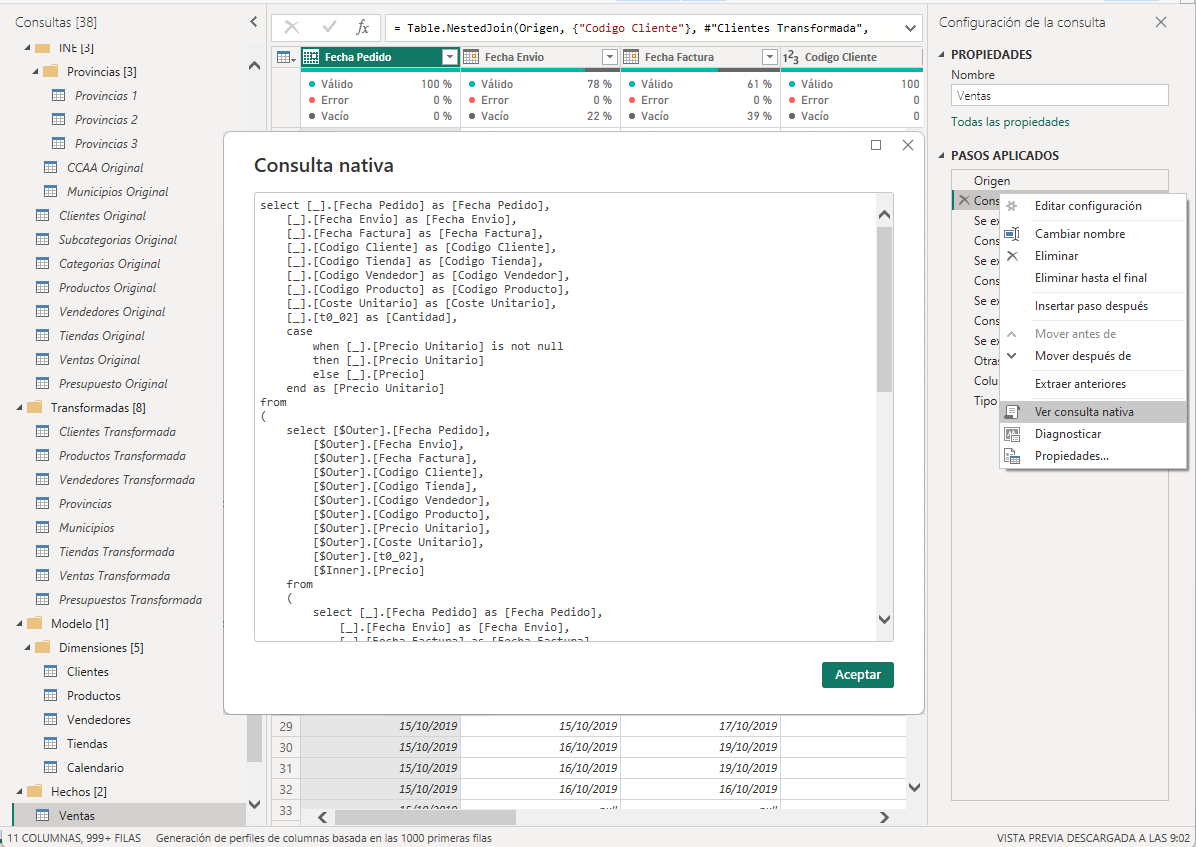
Impacto en el rendimiento de las consultas
Mientras las consultas de las capas Originales y Transformadas no se carguen al modelo podemos garantizar que el rendimiento de las consultas no se afecta porque al final solo se estará cargando una sola consulta con todas las transformaciones.
En el libro nos dicen que separar las consultas no ralentiza la actualización y nos explican que Power Query aprovecha una tecnología llamada “Node caching”, que almacena en caché los resultados de la primera actualización en una secuencia y luego los reutiliza para otras consultas en la misma sesión de actualización.
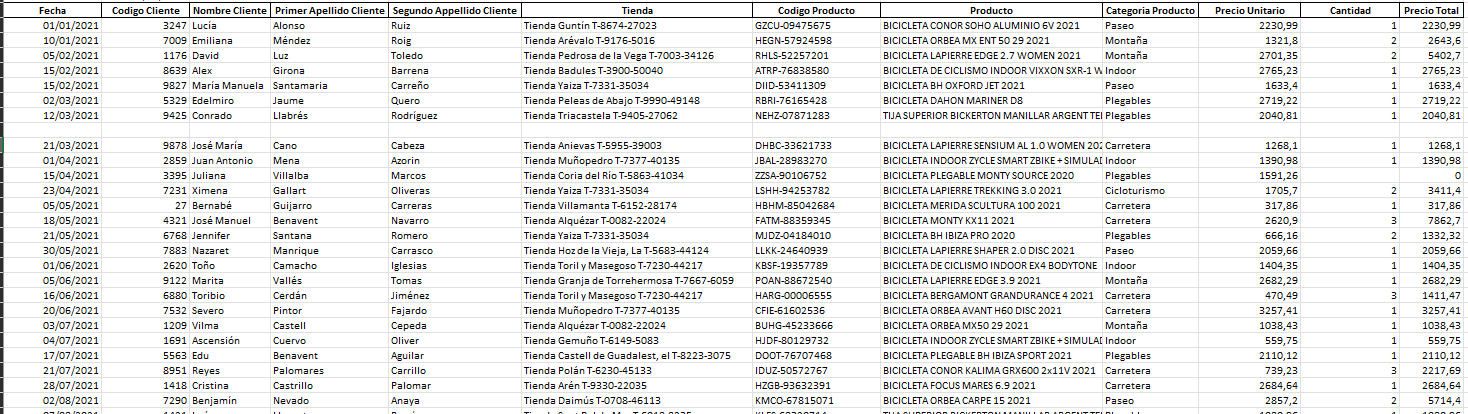
Por ejemplo, supongamos que tenemos un origen único como el que se muestra en la imagen. Es un archivo CSV que contiene los datos de venta de una empresa.
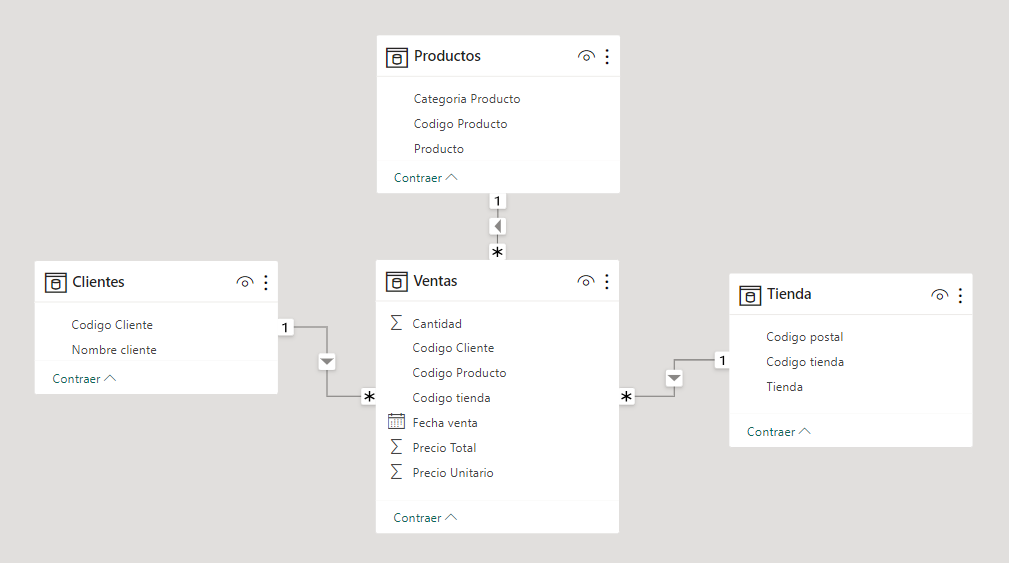
Y queremos crear a partir de esa fuente de datos un modelo como el que se muestra en la siguiente imagen:
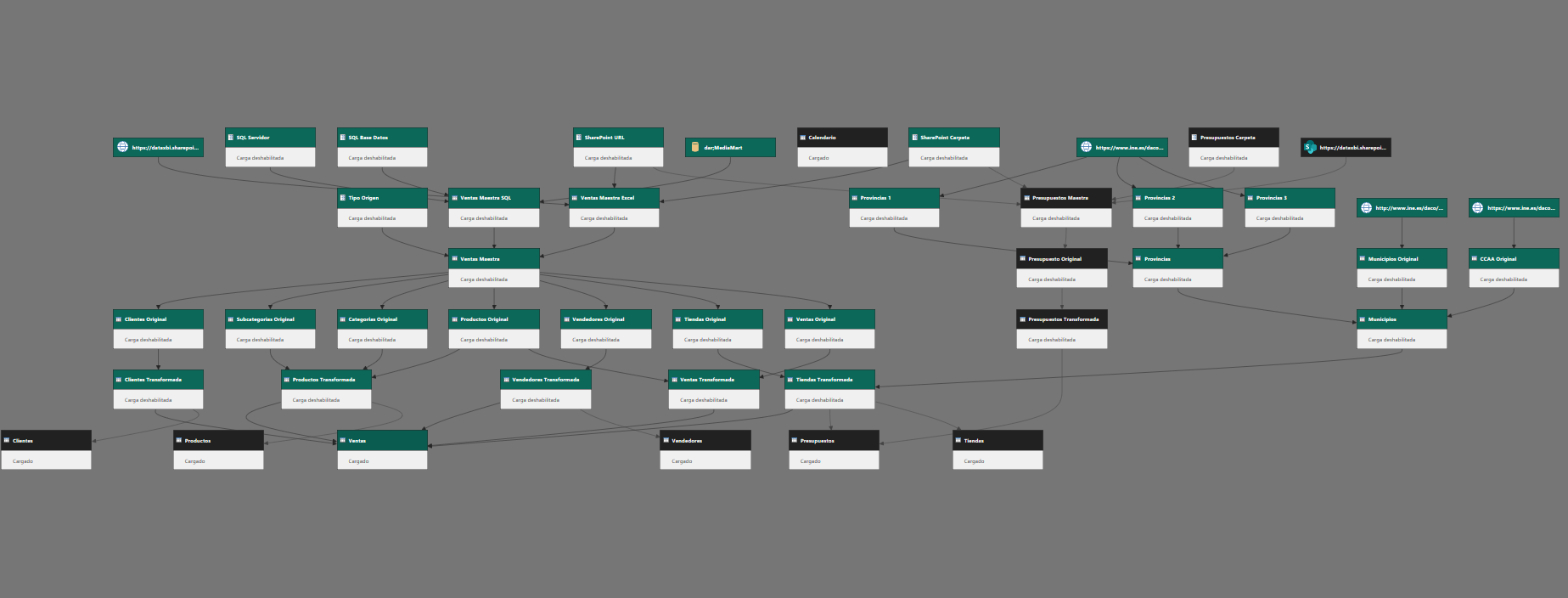
Aplicando esta técnica la arquitectura que nos queda sería como la de la siguiente imagen.
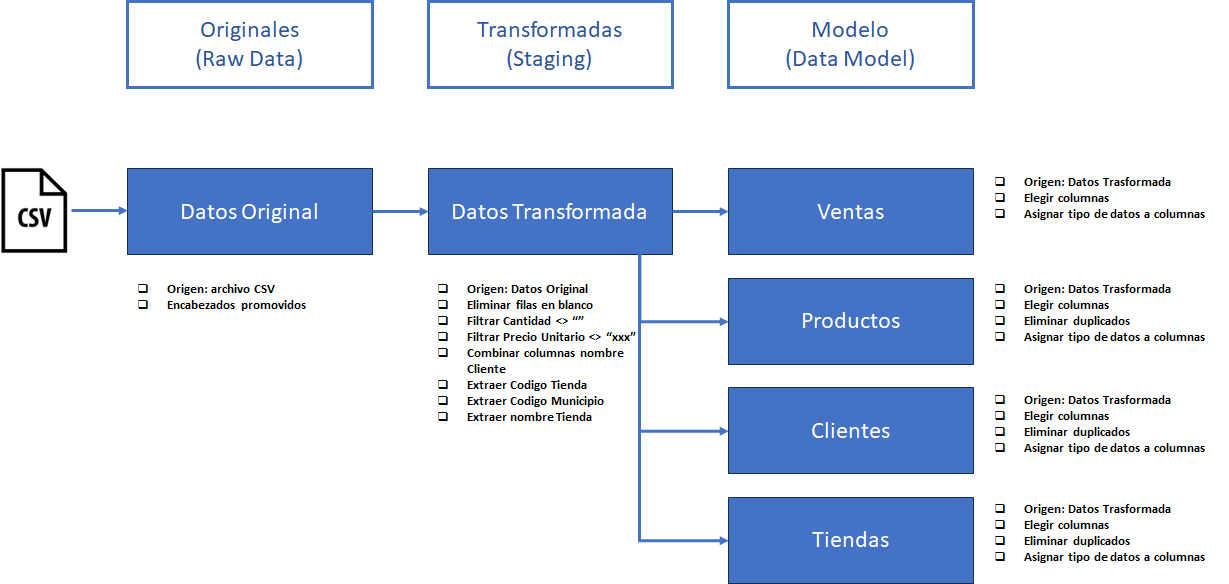
Las consultas Ventas, Productos, Tiendas y Clientes, de la capa Modelo hacen referencia a la consulta Datos Transformada de la capa Transformadas. En la imagen podemos ver como quedan organizadas las consultas en Power Query.
Cuando se actualice la consulta Datos Transformada se generará una vez y se almacenará en cache. A continuación la consulta Ventas hará referencia a la versión almacenada en cache de Datos Transformada, aplicará sus propias transformaciones y luego cargará la tabla en el destino. Lo mismo ocurrirá con el resto de consultas: Productos, Tiendas y Clientes.
Los resultados de la consulta de transformación solo se generan una vez, y se utilizan en varias consultas de la capa Modelo. Si en lugar de aplicar esta técnica en este ejemplo hubiéramos creado una única consulta para cada tabla del modelo, tendríamos pasos duplicados en todas las consultas y esto si afectaría al rendimiento.
Ventajas y desventajas del uso de esta técnica
Ventajas de tener varias consultas
Facilita la exploración de los datos de origen:
Seleccionando la consulta correspondiente de la capa Originales podremos ver y explorar los datos tal cuál están en el origen de datos.
Se pueden reusar consultas de un nivel anterior, evitando duplicidades:
Se pueden crear nuevas consultas que hagan referencia a las consultas de las capas Originales y Transformadas sin necesidad de repetir todo el proceso de obtenerlas y duplicar los pasos.
Mejora el mantenimiento de la solución cuando cambia un origen de datos:
Si cambia un origen de datos y tenemos una única consulta que contiene todos los pasos tendríamos que modificar dicha consulta. En cambio, sí utilizamos la arquitectura Multi-Query basta con crear una consulta que conecte con el nuevo origen de datos y luego en la consulta correspondiente de la capa Transformadas cambiar la referencia a la nueva consulta, el resto permanece igual. Solo hay que tener en cuenta que las columnas en el nuevo origen deben tener los mismos nombres que la original.
Formula Firewall:
Si bien hay casos que requieren mantener sus fuentes de datos en una consulta para evitar el Firewall de fórmula, también hay casos en los que debe separar sus consultas para evitarlo.
Desventajas de tener varias consultas
Se incrementa el número de consultas por lo que puede ser más difícil seguir el linaje.
Cuando tenemos pocas consultas es muy rápido encontrar la que se necesita. En cambio si son muchas puede costar más trabajo, sobre todo porque el navegador de Power Query no tiene un buscador que facilite la tarea. Una buena práctica para solucionar este problema es agrupar las consultas por capas y nombrarlas de forma apropiada para que se pueda identificar fácilmente cada consulta dentro de cada capa.
Conclusiones
Esta claro que separar una consulta en múltiples consultas es más trabajoso que tener todos los pasos en una única consulta pero pienso que son más las ventajas que las desventajas de hacerlo, sobre todo para el mantenimiento y reutilización de los datos.
No todas las consultas necesitan dividirse en los mismos niveles, depende de la cantidad y complejidad de las transformaciones que se realicen y el objetivo de su proyecto.
En la medida que vayas desarrollando proyectos irás ajustando la opción que más te convenga a ti.