Jugando con DuckDB
Este es mi primer acercamiento a DuckDB, un gestor de base de datos SQL concebido para tareas analíticas (OLAP) que es muy pequeño pero muy potente y además es de código abierto.
Quiero compartir en esta entrada de blog varias cosas que he probado:
- La aplicación Tad que es un visor de ficheros CSV y Parquet y que utiliza DuckDB
- Utilizar DuckDB para hacer una consulta SQL a un fichero Parquet remoto (HTTP)
- Crear una base de datos en DuckDB a partir de ficheros Parquet y CSV
- Utilizar DuckDB para convertir ficheros CSV a Parquet desde la línea de comandos
- Utilizar DuckDB desde Python para hacer una consulta SQL sobre una carpeta con ficheros Parquet
- También desde Python, utilizar DuckDB para hacer una consulta SQL donde se combinen dos DataFrame pandas
¿Qué es DuckDB?
Como decía al inicio, DuckDB es un gestor de base de datos muy pequeño porque ha sido creado para que se pueda ejecutar dentro de cualquier aplicación. Si conoces SQLite, son similares en este aspecto. Pero se diferencia de SQLite en que los datos se almacenan en columnas porque DuckDB está concebido para hacer tareas de análisis de datos, donde la agregación de los datos de las columnas tiene un gran peso.
Una característica muy importante de DuckDB es que es muy rápido tanto cargando los datos como ejecutando las consultas SQL, porque utiliza una tecnología que optimiza el uso del CPU. Yo conocí DuckDB por las publicaciones de Mimoune Djouallah y él ha hecho varias demostraciones de la velocidad de procesamiento de DuckDB.
Además, DuckDB es capaz de ejecutar consultas directamente sobre ficheros Parquet o CSV.
Tad
Comenzaré este recorrido mencionando la aplicación de escritorio Tad que utiliza internamente DuckDB para leer, visualizar y filtrar ficheros Parquet y CSV y también las tablas de bases de datos DuckDB y MySQL. Tad es multiplataforma, gratuita y de código abierto y la puedes descargar desde https://www.tadviewer.com/.
Esta aplicación me parece genial para explorar los ficheros porque los datos se cargan muy rápido y se pueden filtrar aplicando criterios sobre las columnas. Además se pueden agrupar varias columnas y hacer operaciones de agregación para construir una tabla pivote. Luego los datos filtrados se pueden exportar a un fichero CSV.
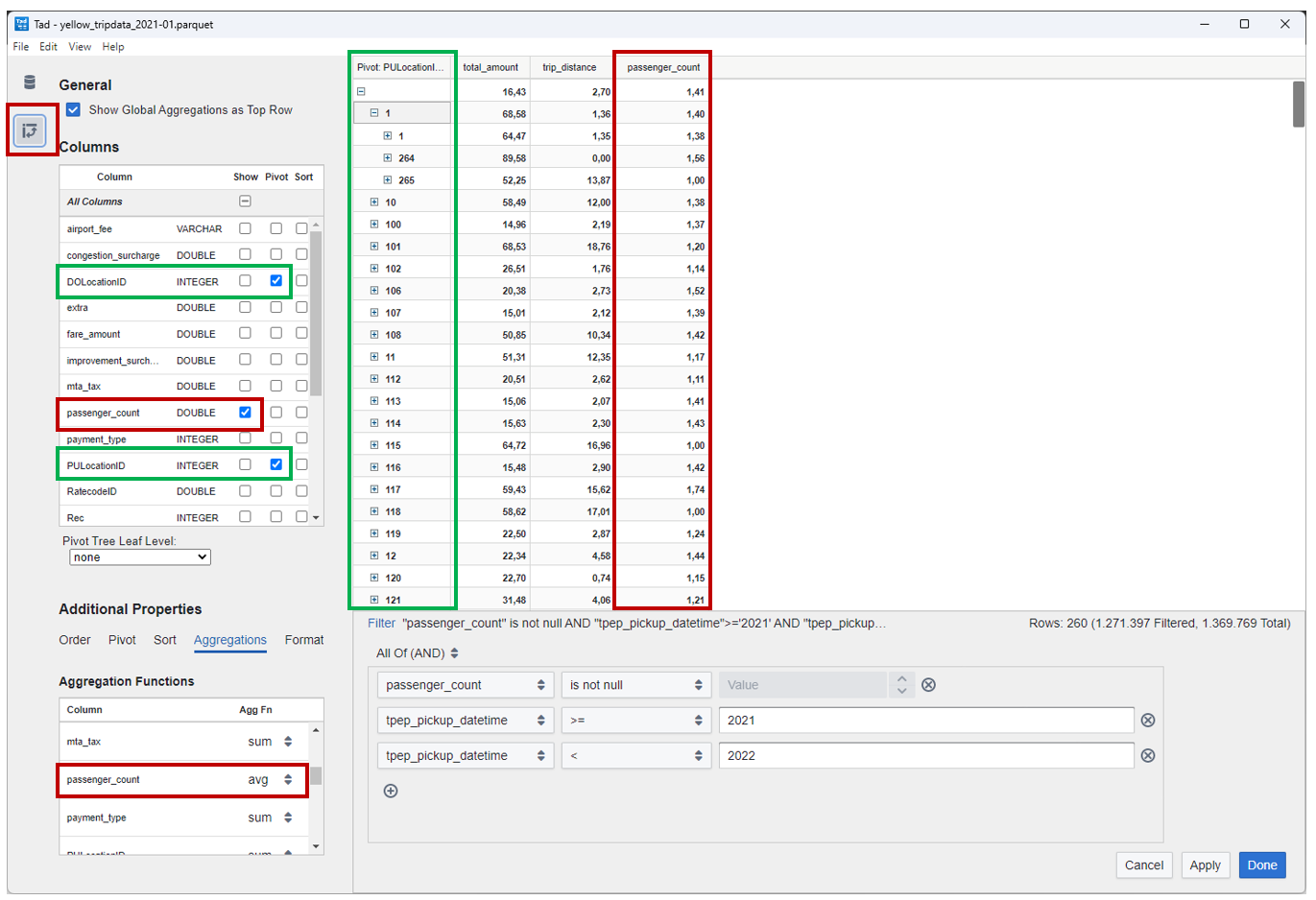
En la imagen se puede ver una tabla pivote de un fichero Parquet con los datos de los viajes de los taxis amarillos de New York, donde se han agrupado las columnas del sitio de salida y el sitio de llegada y se han calculado los promedios del importe total de viaje, la distancia y el número de pasajeros.
Consulta SQL a un fichero Parquet remoto (HTTP)
En la siguiente parada de este recorrido voy a utilizar el cliente de línea de comando (CLI) de DuckDB, que se puede descargar desde https://duckdb.org/docs/installation/index. No hace falta instalarlo, sólo expandir el ZIP y copiar el ejecutable para una carpeta. Luego abrimos una línea de comandos desde la carpeta y ejecutamos el programa duckdb.exe y nos aparecerá un prompt donde podremos ejecutar comandos SQL y otros comandos de control. Si has usado el CLI de SQLite, este te resultará familiar.
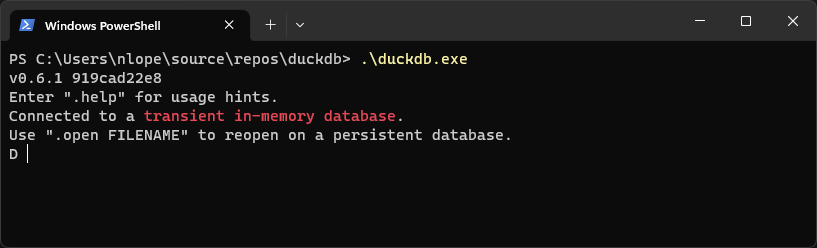
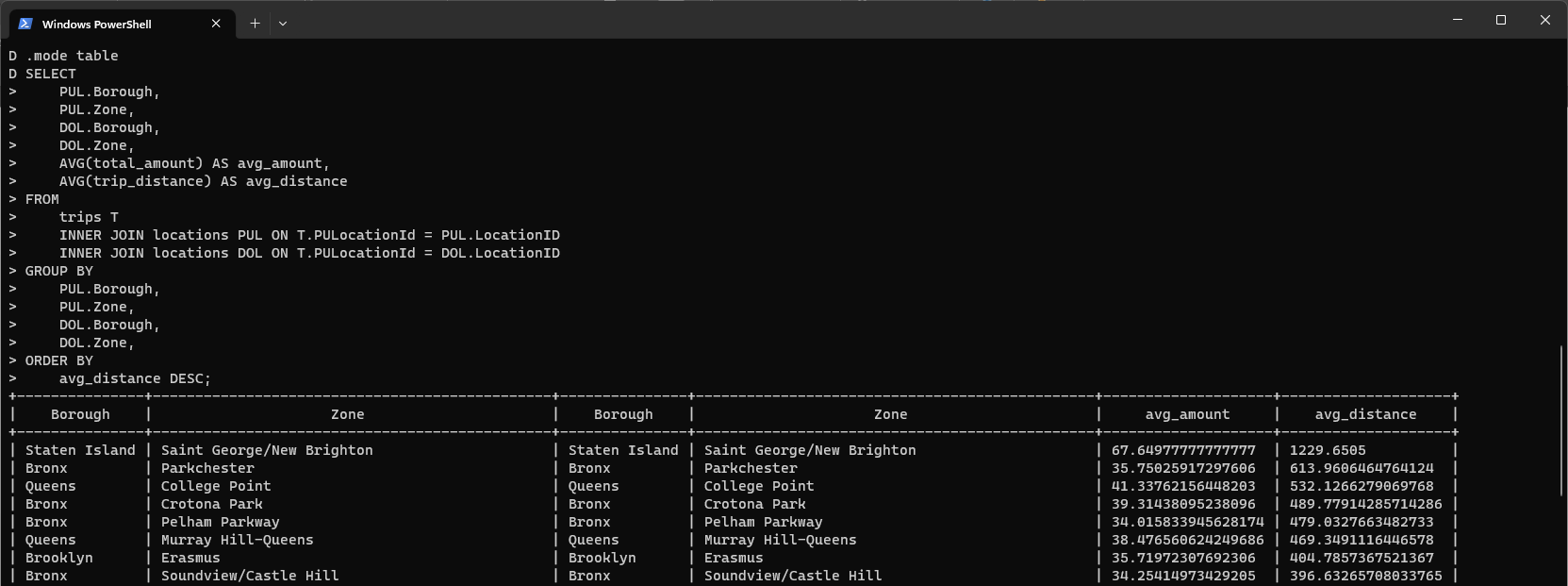
He ejecutado una consulta SQL contra uno de los fichero Parquet con los datos de los viajes de los taxis de New York, sin cargarlos en la base de datos. Y para hacerlo más interesante he consultado el fichero directamente desde el origen, sin descargarlo a una carpeta local. Para ello he usado una de las extensiones que están disponibles para DuckDB, en este caso la extensión HTTPFS con la cual podemos usar un URL para indicar la ruta al fichero.
En la imagen muestro una captura de pantalla con los comandos que he usado en el CLI. En las dos primeras líneas se instala y se carga la extensión HTTPFS. En el resto de las líneas está la consulta SQL donde se agrupan los datos por el sitio de salida y el sitio de llegada y se calculan los promedios del importe del viaje y de la distancia recorrida, y se ordenan por el promedio de la distancia, de mayor a menor. En el FROM de la consulta SQL he usado la función read_parquet() de DuckDB, que recibe como argumento la ruta al fichero Parquet, y que en este caso gracias a la extensión HTTPFS es un URL. En la imagen también se ven los resultados de la consulta.
Crear una base de datos en DuckDB a partir de ficheros Parquet y CSV
Me mantengo en el CLI para crear una base de datos DuckDB con dos tablas, una tabla para guardar los datos de los viajes de los taxis y otra tabla para guardar el listado de los sitios de salida y llegada. Los datos de la primera tabla se cargarán desde 12 ficheros Parquet con los viajes de los taxis en el año 2021, un archivo por mes. Mientras que para los datos de la segunda tabla utilizaré un fichero CSV. Todos los ficheros están en una carpeta local.
Estos son los comandos que he utilizado para crear la base de datos y las tablas:
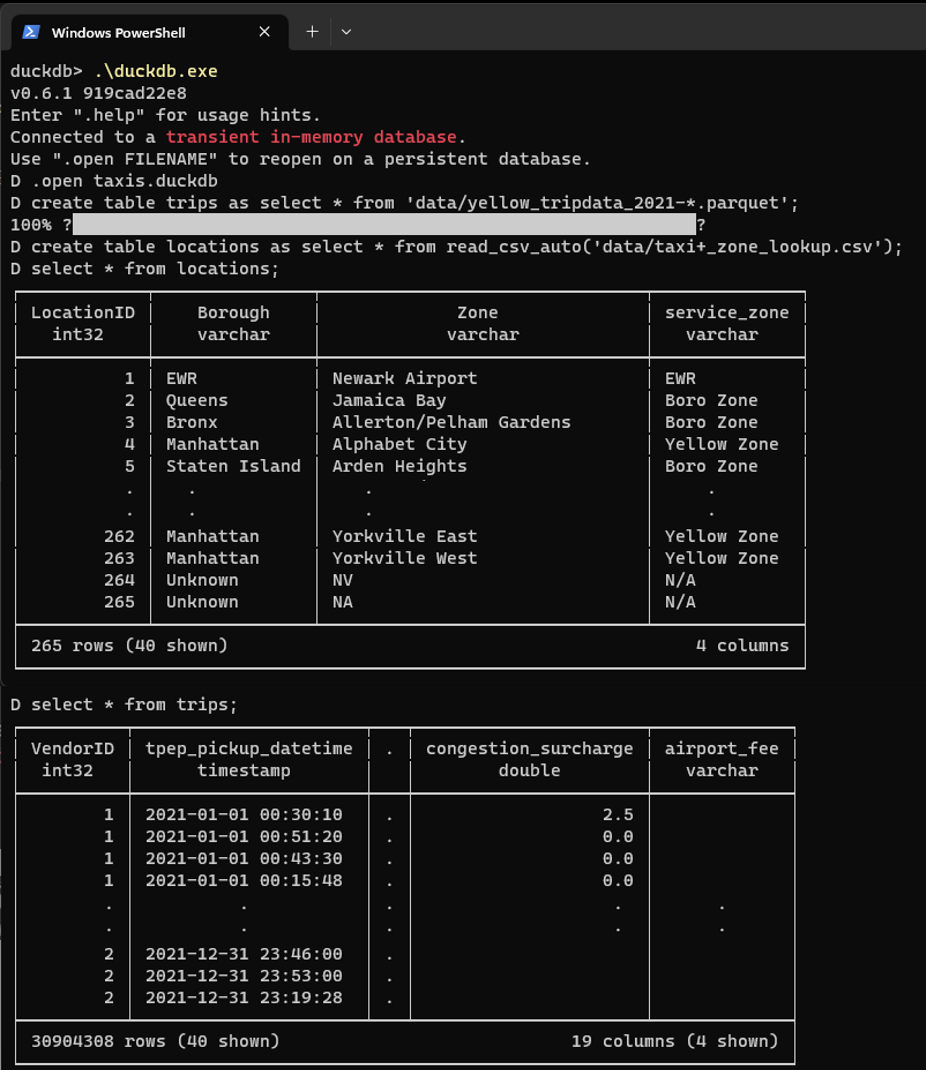
.open taxis.duckdb
Este comando crea una base de datos, que se guardará en un fichero con el nombre taxis.duckdb en la carpeta local. O si ya existía un fichero con este nombre, se cargará la base de datos. El punto delante de open indica que es un comando especial del CLI y no una expresión SQL.
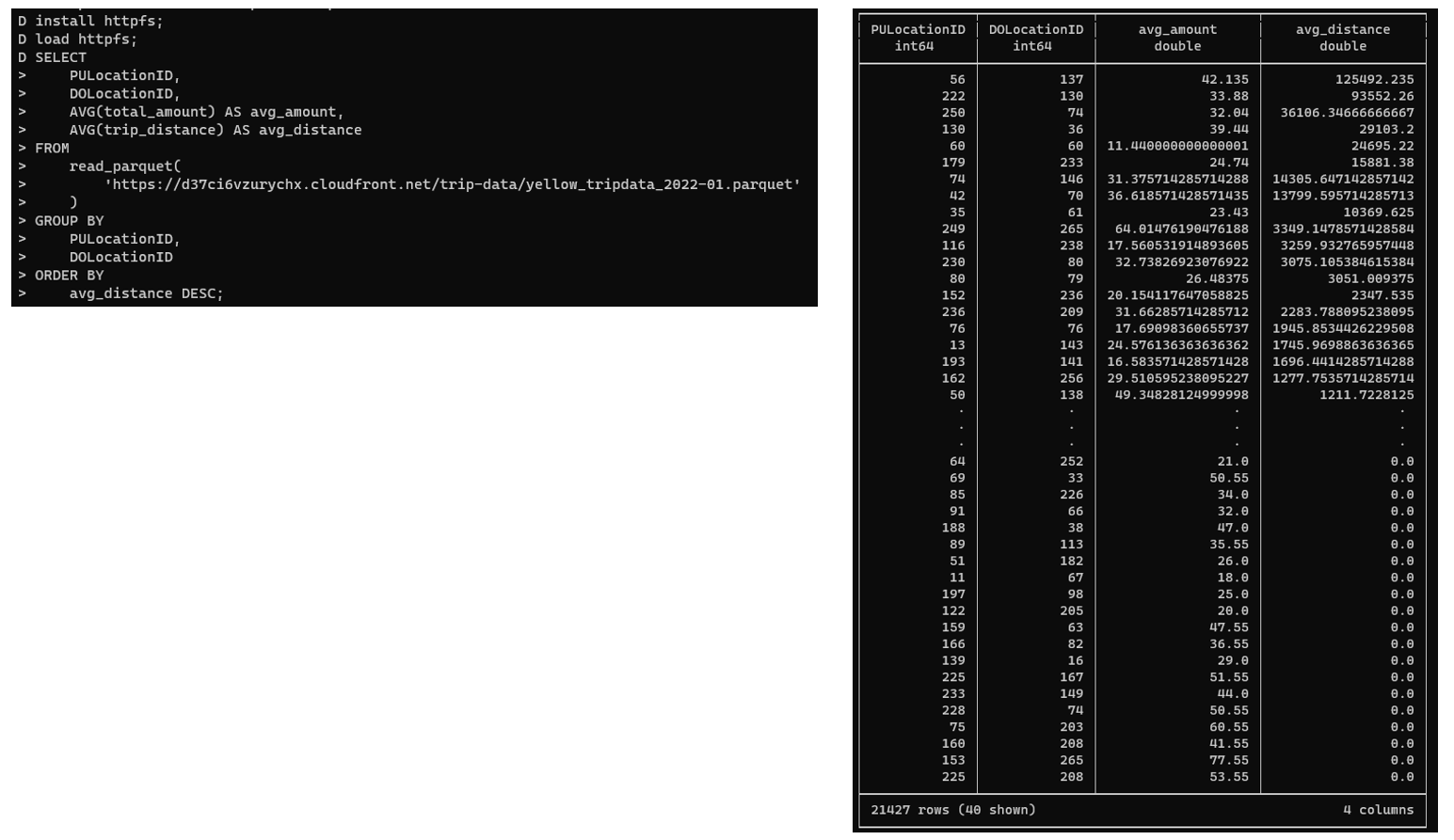
CREATE TABLE trips AS SELECT * FROM 'data/yellow_tripdata_2021-*.parquet';
Esta expresión SQL crea la tabla trips a partir de los ficheros Parquet. En el FROM se indica directamente una ruta, que incluye un asterisco para que se lean todos los ficheros que cumplan con el patrón. Los nombres y los tipos de las columnas de la tabla se toman de los metadatos de los ficheros Parquet. Además de crear la tabla, se cargan los datos de todos los ficheros. En el CLI, las expresiones SQL siempre tienen que terminar con un punto y coma.
CREATE TABLE locations AS SELECT * FROM read_csv_auto('data/taxi+_zone_lookup.csv');
Esta expresión SQL crea la tabla locations a partir de un fichero CSV. La función de DuckDB read_csv_auto() analiza el fichero CSV para extraer los nombres de las columnas y estimar los tipos de datos.
Una vez creada la base de datos y cargados los datos, he hecho una consulta SQL donde se combinan ambas tablas para mostrar el importe promedio y la distancia promedio entre cada sitio de salida y de llegada.
Utilizar DuckDB para convertir ficheros CSV a Parquet desde la línea de comandos
En esta nueva parada del recorrido voy a utilizar DuckDB para convertir un fichero CSV a Parquet. Y lo haré directamente desde la línea de comandos, en lugar de hacerlo de manera interactiva entrando al CLI de DuckDB.
Para ello, he abierto una línea de comandos en la carpeta donde tengo copiado duckdb.exe y donde también tengo un fichero CSV y he ejecutado este comando:
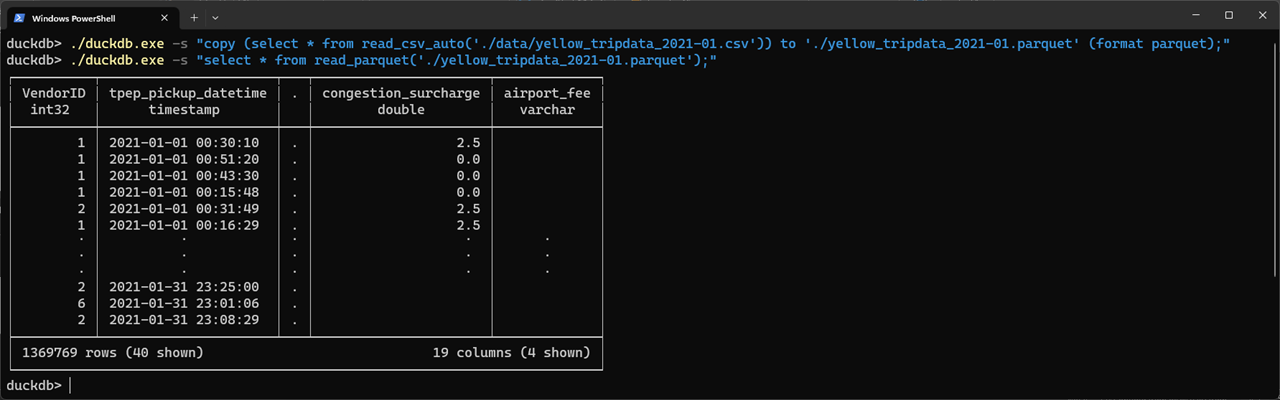
duckdb.exe -s "copy (select * from read_csv_auto('./yellow_tripdata_2021-01.csv')) to './yellow_tripdata_2021-01.parquet' (format parquet);"
El parámetro -s le indica a duckdb.exe que ejecute el comando que viene a continuación. El comando, que está entre comillas dobles, tiene dos partes:
- Con la expresión
select * from read_csv_auto('./yellow_tripdata_2021-01.csv')se leen todos los datos del fichero CSV - Con la expresión
copy ... to './yellow_tripdata_2021-01.parquet' (format parquet)se guardan los datos en un fichero Parquet
En la imagen siguiente se puede ver la ejecución del comando, y a continuación la ejecución de otro comando con una consulta SELECT para mostrar el contenido del fichero Parquet.
Utilizando este comando he preparado un script en PowerShell que lee todos los ficheros CSV de una carpeta y los convierte a ficheros Parquet, y que muestro en la siguiente imagen.

Utilizar DuckDB desde Python para hacer una consulta SQL sobre una carpeta con ficheros Parquet
Los dos últimas paradas de este recorrido serán con Python, usando la API Python de DuckDB.
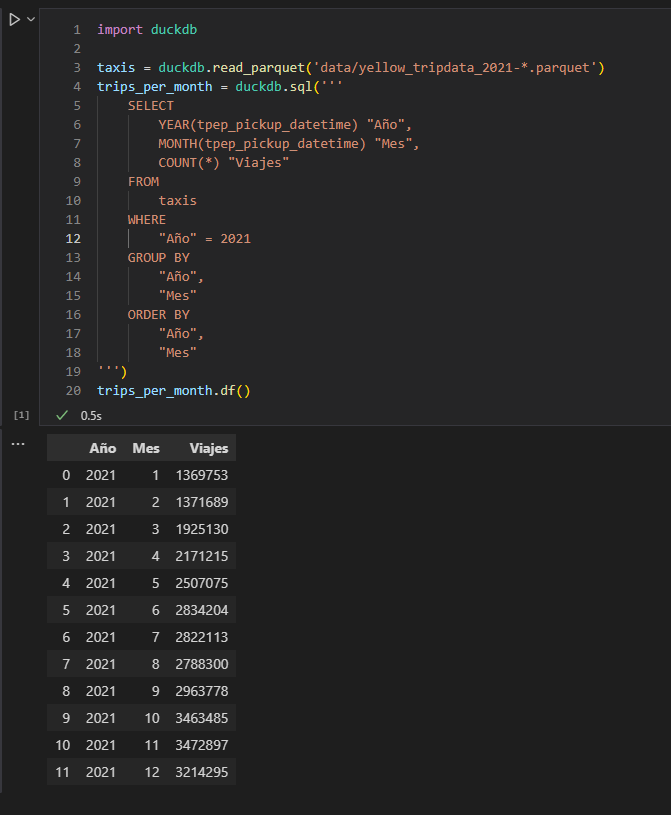
En el primer ejemplo con Python he usado DuckDB para leer los ficheros Parquet de una carpeta con los viajes de los taxis amarillos de New York, hacer una consulta SQL para contar los viajes para cada mes del año 2021 y he guardado el resultado de la consulta en un DataFrame pandas.
En la imagen de abajo muestro el código, donde los puntos importantes son:
import duckdb
Se importa la API de DuckDB, que debe haber sido instalada antes en el entorno Python con un comando como pip install duckdb.
taxis = duckdb.read_parquet('data/yellow_tripdata_2021-*.parquet')
Con la función duckdb.read_parquet() se crea una consulta SQL que puede leer los datos de los ficheros Parquet con los viajes de los taxis del año 2021, y que se guarda en la variable taxis. Esta variable no contiene los datos, sino una representación simbólica de una consulta SQL, que en DuckDB se llama Relation. La variable taxis se puede usar dentro de otras consultas SQL, de manera que la consulta final se va construyendo paso a paso, y sólo se ejecutará cuando el resultado se imprima o se extraiga hacia otra estructura de datos.
trips_per_month = duckdb.sql(...)
La función duckdb.sql() construye una consulta SQL para agrupar los viajes por meses y contarlos. El FROM de la consulta usa la variable taxis que se creó en el paso anterior. El resultado de la función se guarda en la variable trips_per_month, que es otra Relation, o sea no guarda los datos porque la consulta aún no se ha ejecutado.
trips_per_month.df()
Finalmente, la función df() ejecuta la consulta SQL y la guarda en un DataFrame pandas.
Utilizar DuckDB desde Python para hacer una consulta SQL donde se combinen dos DataFrame pandas
Y para terminar este recorrido con DuckDB, he hecho otro script Python que combina datos de dos DataFrame pandas con una consulta SQL.
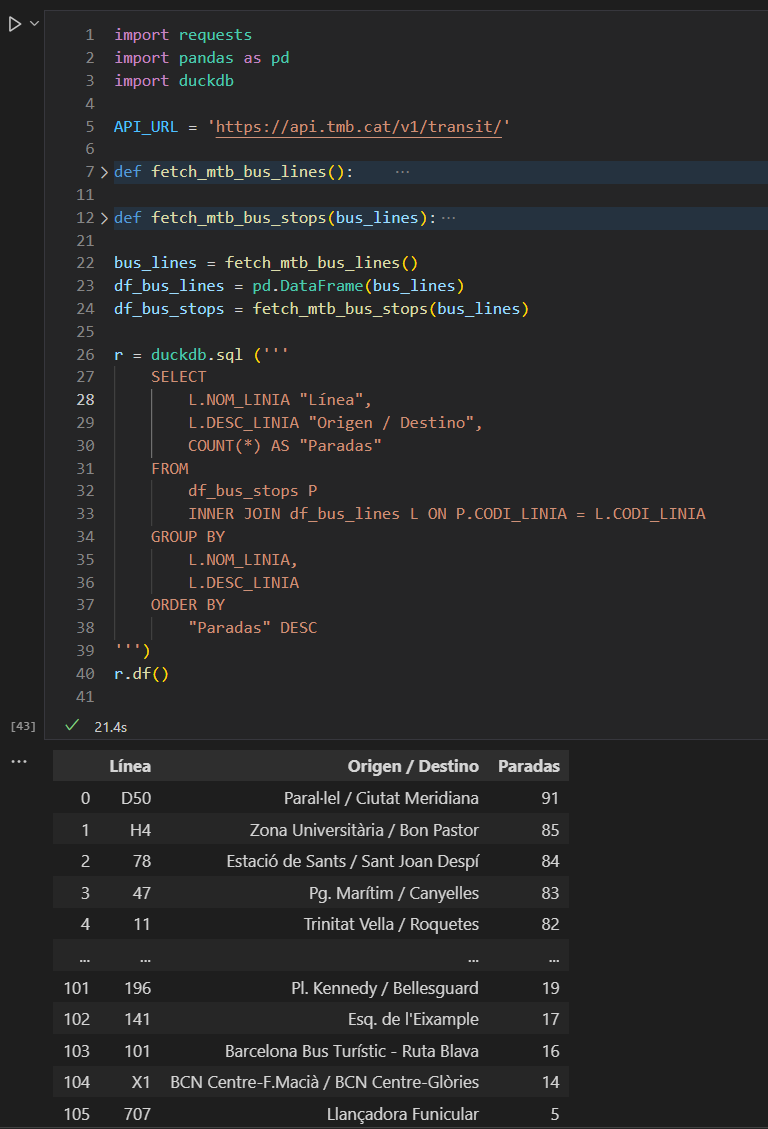
Los datos esta vez no provienen de ficheros Parquet, sino de de la API de la red de transporte de Barcelona (TMB). Primero me he conectado a la API para obtener los datos de las rutas de autobuses de Barcelona y con esos datos he creado un DataFrame que he guardado en la variable df_bus_lines. Me he vuelto a conectar a la API para obtener los datos de las paradas de cada línea de autobús y he creado otro DataFrame que he guardado en la variable df_bus_stops.
Una vez obtenidos los datos, he usado la función duckdb.sql(...) para crear una consulta SQL que combine con un JOIN ambos DataFrames para obtener un listado con la cantidad de paradas en cada línea. Al construir la consulta SQL se indican los nombres de las variables que contienen los DataFrames en el FROM y en el JOIN, y la librería de DuckDB para Python busca dichas variables en el entorno global y las usa como si fueran tablas.
Luego, la función df() ejecuta la consulta SQL y la guarda en otro DataFrame pandas.
La siguiente imagen muestra parte del código y el resultado del la consulta.
Conclusiones
Luego de hacer estas pruebas iniciales, mi conclusión es que voy a incluir DuckDB entre las herramientas que utilizo.
Creo que es muy útil poder usar el CLI de DuckDB para convertir ficheros CSV a Parquet y que puede facilitar la implementación de automatizaciones.
También creo que es muy interesante poder usar SQL tanto para trabajar directamente con ficheros Parquet o CSV como con DataFrame pandas.