Power BI y Synapse: Archivos Parquet
Los archivos Parquet son cada vez más utilizados, por lo que es útil conocer opciones para importarlos a Power BI.
En esta entrada hablo del formato Parquet, de cómo crear y leer archivos Parquet, del conector de Power BI para Parquet y de cómo utilizar Synapse para leer archivos Parquet desde un Azure Data Lake.
Parquet
Parquet es un formato de almacenamiento columnar de código abierto que se creó como parte de Apache Hadoop y que actualmente se utiliza en muchos otros sistemas.
Su principal característica es que organiza los datos en columnas, a diferencia de otros formatos que los organizan en filas, como CSV. Además, a cada columna se le asigna un tipo de dato. Esto tiene varias ventajas, entre ellas quiero resaltar las dos que me parecen más importantes.
La primera ventaja es la reducción del espacio de almacenamiento, ya que los datos de cada columna se pueden codificar de manera independiente, con un algoritmo específico para el tipo de dato de la columna. Por ejemplo, para una columna con textos donde los valores se repitan mucho, en lugar de almacenar directamente el texto de cada fila, se puede crear primero un diccionario con los valores únicos y luego para cada fila almacenar un valor numérico con el índice al diccionario. De esta forma se logra reducir el espacio requerido para almacenar la columna. Parquet soporta varios métodos de codificación.
Por cierto, si lo que he comentado antes te resulta familiar, es porque VertiPaq, el motor de analísis usado por Power BI, emplea una técnica similar.
Además de esta codificación, Parquet también soporta varios tipos de compresión, como Snappy o GZIP, con lo cuál se logra reducir aún más el espacio de almacenamiento.
Para dar una idea de cuanto se comprimen los datos, he convertido un archivo CSV con 11 millones de filas a Parquet. El tamaño en disco del CSV es de unos 500 MB mientras que el tamaño del archivo Parquet es de unos 42 MB.

Por lo tanto, con los archivos Parquet podemos reducir los costes de almacenamiento, sobre todo si estamos usando almacenamiento en la nube como es el caso de Azure Data Lake.
La segunda ventaja es que las columnas se pueden leer de manera independiente, o sea, si sólo se quieren obtener los datos de algunas columnas, estos se pueden ir a buscar directamemte, sin necesidad de cargar los datos de las columnas restantes. Esto es muy importante cuando trabajamos con Synapse, porque nos va a permitir aumentar el rendimiento y reducir costes, como veremos más adelante.
Otras dos características muy importantes de Parquet son:
- Metadatos: además de los datos, guarda información sobre los nombres y los tipos de las columnas, estadísticas de los datos, entre otras cosas.
- Estructuras aninanadas: es capaz de representar datos con una estructura compleja, por ejemplo, que una columna contenga a su vez otra tabla.
¿Cómo puedo crear un archivo Parquet?
Hay varias herramientas y bibliotecas con las que podemos crear archivos Parquet.
Por ejemplo, en Python podemos usar la biblioteca pandas para convertir un archivo CSV a Parquet con tan solo tres línea de código.

En el código anterior, pandas está usando implicitamente la biblioteca pyarrow para crear el archivo Parquet.
Con Synapse tenemos varias opciones para crear archivos Parquet.
Por ejemplo, podemos crear un conjunto de datos de integración que utilice como almacenamiento Azure Data Lake Gen2 y como formato Parquet, y luego crear una canalización que lo use como receptor.

También es posible crear archivos Parquet con Synapse usando el grupo de Spark o el grupo SQL sin servidor.
¿Cómo puedo leer un archivo Parquet?
El contenido de un archivo Parquet no es legible directamente, a diferencia de un archivo CSV, por lo que necesitamos usar una aplicación o una biblioteca que entienda el formato.
Por ejemplo, para Windows tenemos la aplicación de código abierto ParquetViewer con la que podemos hacer consultas sobre los datos y ver los metadatos.
En las siguientes imágenes se pueden ver unos pantallazos de la aplicación. El primero muestra todas las columnas de un archivo Parquet, el segundo muestra solo algunas columnas, y el tercero muestra una parte de los metadatos.
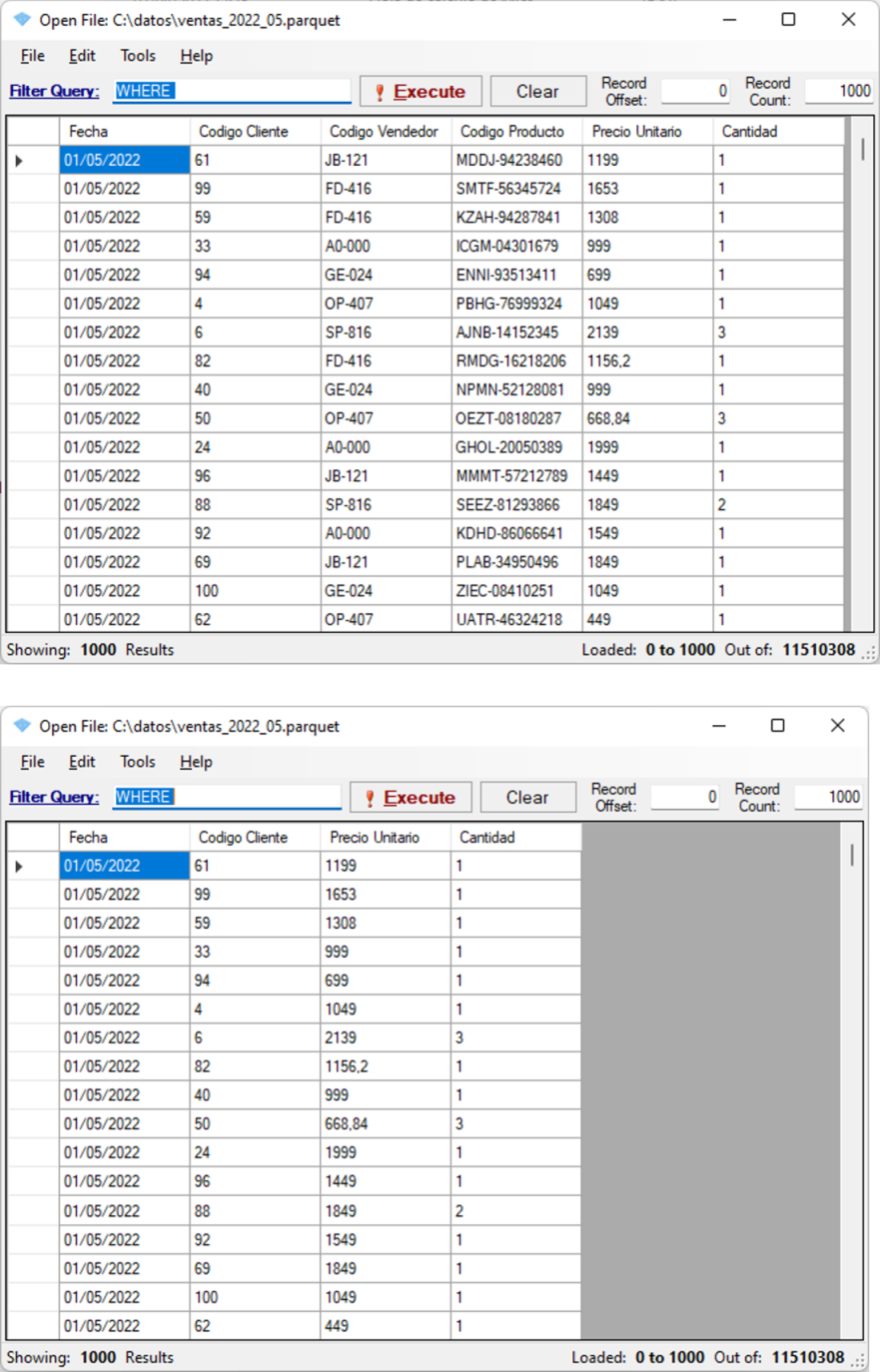
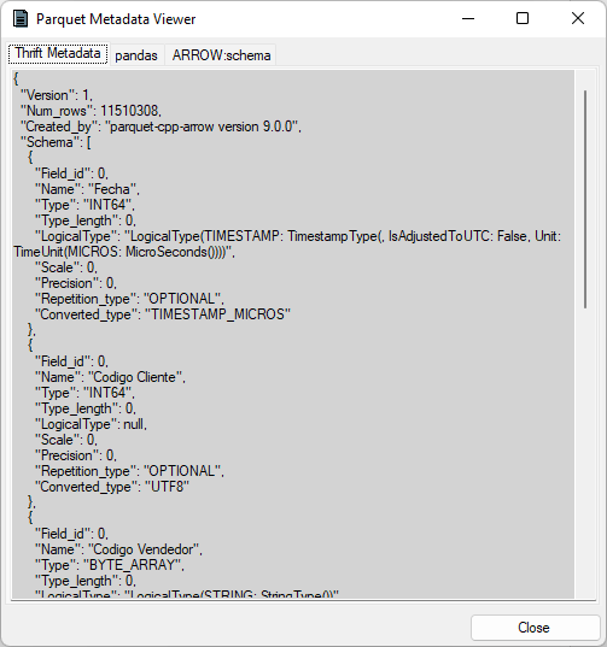
Una aclaración, en la tienda de Windows se puede encontrar la aplicación gratuita Apache Parquet Viewer, pero no la recomiendo porque es más limitada que ParquetViewer y ya no está mantenida por su creador.
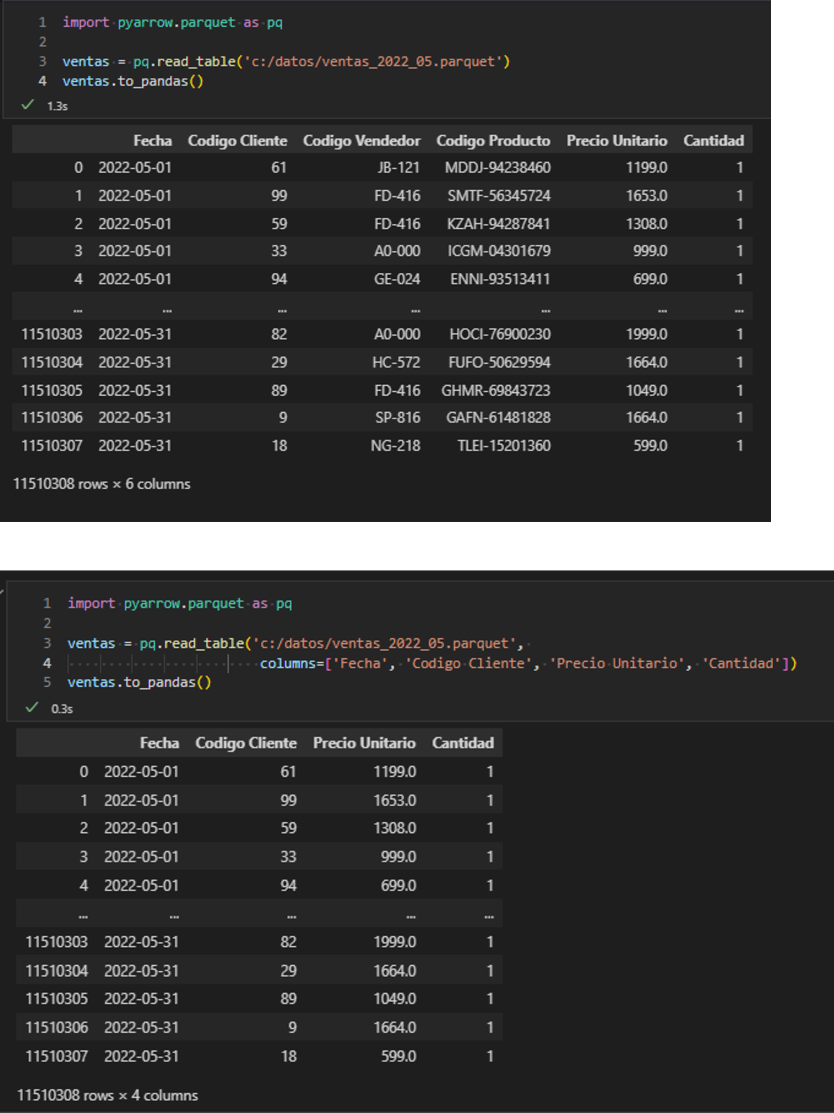
Otro ejemplo, esta vez usando la biblioteca pyarrow de Python. En el primer pantallazo de abajo se puede ver cómo leer todas las columnas y guardarlas en un DataFrame de pandas. En el segundo pantallazo se muestra cómo leer algunas columnas. Y en el tercer pantallazo se leen algunos metadatos.
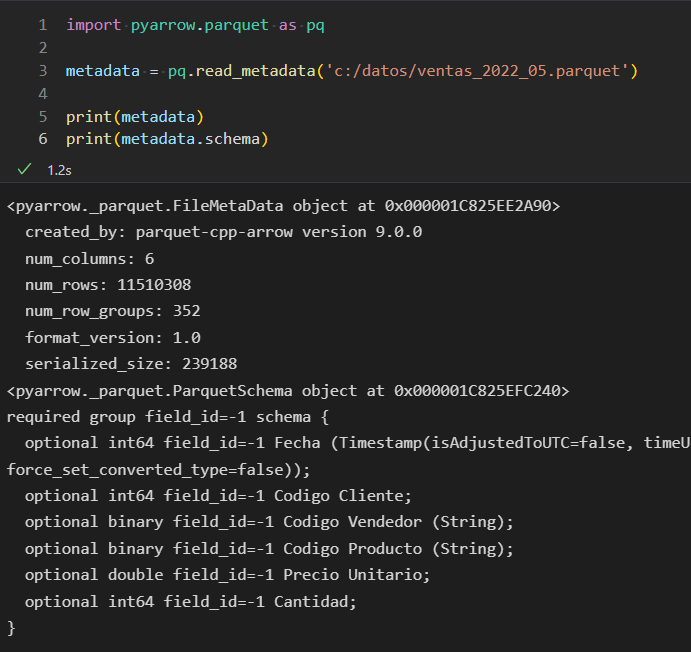
Con Synapse también podemos leer archivos Parquet, de lo que hablaré en breve.
Pero antes quiero comentarte sobre el conector Parquet que tiene Power BI.
Conector Parquet de Power BI
Pues si, Power BI tiene un conector Parquet con el que podemos leer directamente los datos de estos archivos.
Cuando lo usamos debemos indicar una dirección URL de un archivo Parquet.
Si queremos leer un archivo local podemos escribir su ruta, por ejemplo c:/datos/ventas_2022_05.parquet lo que generará un código Power Query M como este
Parquet.Document(File.Contents("c:/datos/ventas_2022_05.parquet"))
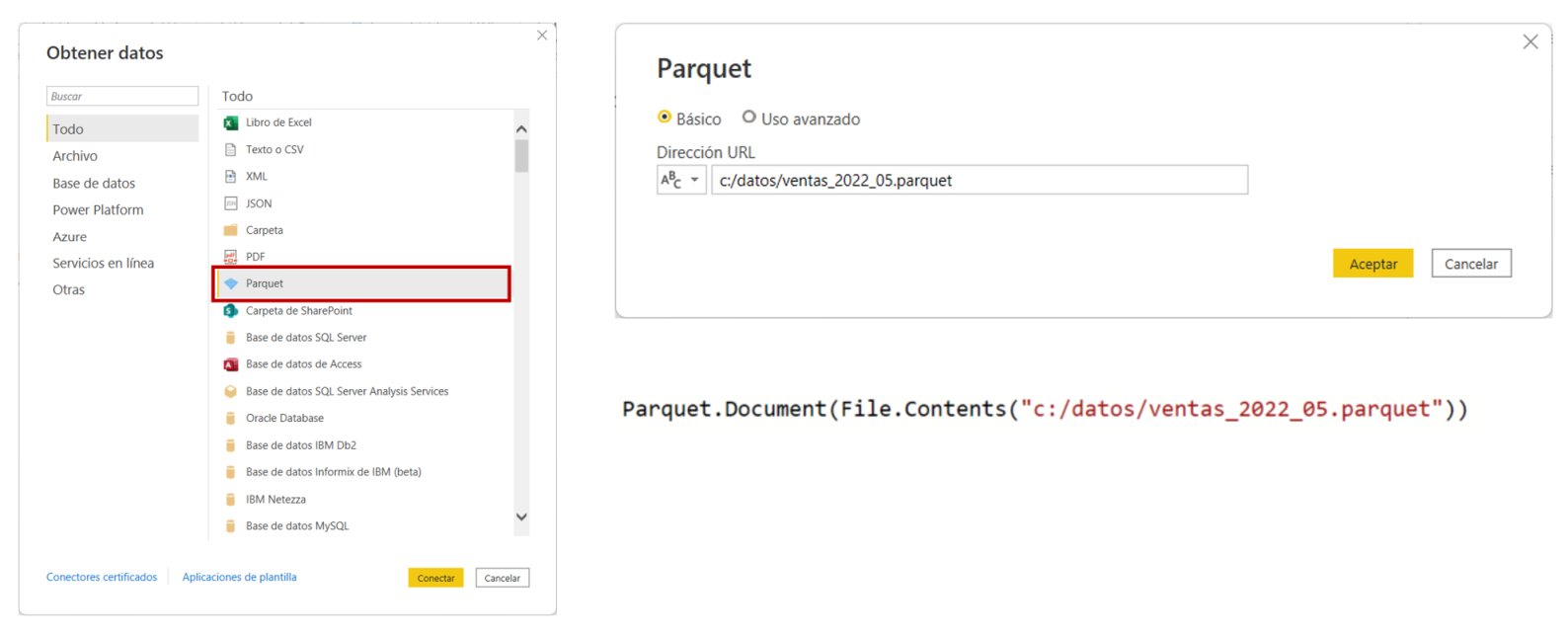
Para conectarnos a un archivo Parquet en un Azure Data Lake Gen2, debemos usar un URL como este https://xxx.dfs.core.windows.net/ventas/parquet/ventas_2022_05.parquet donde xxx es el nombre de la cuenta de almacenamiento. Lo que generará un código Power Query M como este
Parquet.Document(AzureStorage.DataLakeContents("https://xxx.dfs.core.windows.net/ventas/parquet/ventas_2022_05.parquet"))
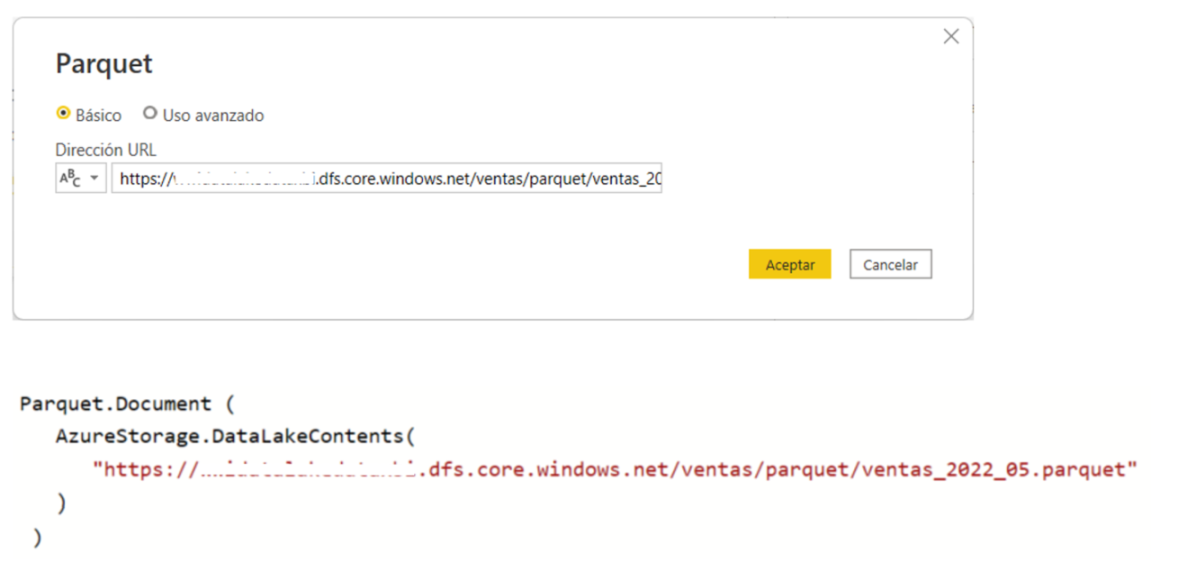
Como puedes ver en el código Power Query M, ambos casos tienen en común el uso de la función Parquet.Document que es la que entiende el formato Parquet. La diferencia está en las funciones que se encargan de leer el archivo desde el soporte de almacenamiento y que en los dos ejemplos anteriores son File.Contents y AzureStorage.DataLakeContents, pero pudieran usarse otras.
Este conector aprovecha algunas de las ventajas del formato Parquet, pero no todas. Para profundizar más en este asunto te invito a leer los artículos de Chris Webb sobre el tema.
Yo hice varias pruebas, importando un archivo Parquet, con un tamaño de 42 MB, desde una carpeta local y desde un Azure Data Lake Gen2, y obtuve estos resultados:
| Prueba | Origen | MB leidos por Power BI | Comentarios |
|---|---|---|---|
| Cargar todo, sin filtros | Archivo local | 42 MB | Lee todo el archivo. |
| Azure Data Lake Gen2 | 80 MB | Parece que lee todo el archivo. Tendría que investigar por qué es casi el doble del tamaño del archivo. | |
| Filtrar las filas del día 2022-05-15 | Archivo local | 42 MB | Lee todo el archivo. |
| Azure Data Lake Gen2 | 80 MB | Parece que lee todo el archivo. | |
| Seleccionar algunas columnas | Archivo local | 22 MB | Más o menos la mitad del archivo, pero depende de cuantas columnas se seleccionen. |
| Azure Data Lake Gen2 | 80 MB | Parece que lee todo el archivo. | |
| Contar las filas | Archivo local | menos de 1 MB | Parace que sólo lee los metadatos. |
| Azure Data Lake Gen2 | 1,5 MB | Parace que sólo lee los metadatos. |
Con la función Parquet.Document podemos conectarnos a un solo archivo. Si necesitamos importar los datos de varios archivos Parquet que estén en una carpeta, tenemos que usar primero el conector de Carpeta o el conector de Azure Data Lake Storage Gen2 y luego combinar los archivos Parquet. Aquí también te remito al blog de Chris Webb donde demuestra que usando la función Table.Combine se logra mejor rendimiento que expandiendo una columna, como hace Power Query cuando combinamos archivos de una carpeta.
Synapse es una opción interesante cuando tenemos que conectarnos a archivos Parquet que estén almacenados en Azure Data lake Gen2, y es lo que voy a comentar a continuación.
Synapse
Bueno, finalmente he llegado a Synapse! Te vuelvo a recomendar que leas la entrada anterior porque aquí vamos a trabajar con la misma área de trabajo de Synapse y con el mismo contenedor en el Azure Data Lake.
He creado archivos Parquet con los datos de las ventas de cada día para los meses de mayo y junio de 2022. Cada archivo tiene un tamaño aproximado de 20Â MB. En Azure Data Lake, en el contenedor ventas, he creado la carpeta parquet y bajo ella he creado una jerarquía de carpetas para año, mes y día, como se muestra en la imagen.
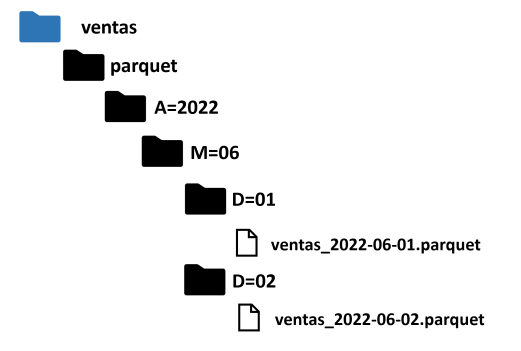
Al particionar los archivos Parquet es común que las carpetas tengan nombres como los que he creado, A=2022, M=06, D=01 porque hay sistemas que al leer estas carpetas, agregan las columnas A,M y D al resultado.
En Synapse voy a seguir usando el grupo SQL sin servidor, donde el coste está en función del volumen de datos utilizdos para procesar las consultas con un cargo mínimo equivalente a 10 MB.
Primero voy a hacer una consulta SQL para traer los datos de un solo archivo, y luego crearé una vista que sea capaz de leer todos los archivos.
Para hacer la primera consulta, desde Synapse Studio buscaré uno de los archivos Parquet que están en Azure Data Lake, dentro del contenedor ventas, que ya está vinculado al área de trabajo de Synapse. Para ello voy a la página Datos de Synapse Studio y navego por el Data Lake hasta entrar en la carpeta ventas/parquet/A=2022/M=06/D=01 y hago clic con el botón derecho del ratón sobre el archivo Parquet y escojo la opción Nuevo script SQL y luego Seleccionar las primeras 100 filas.
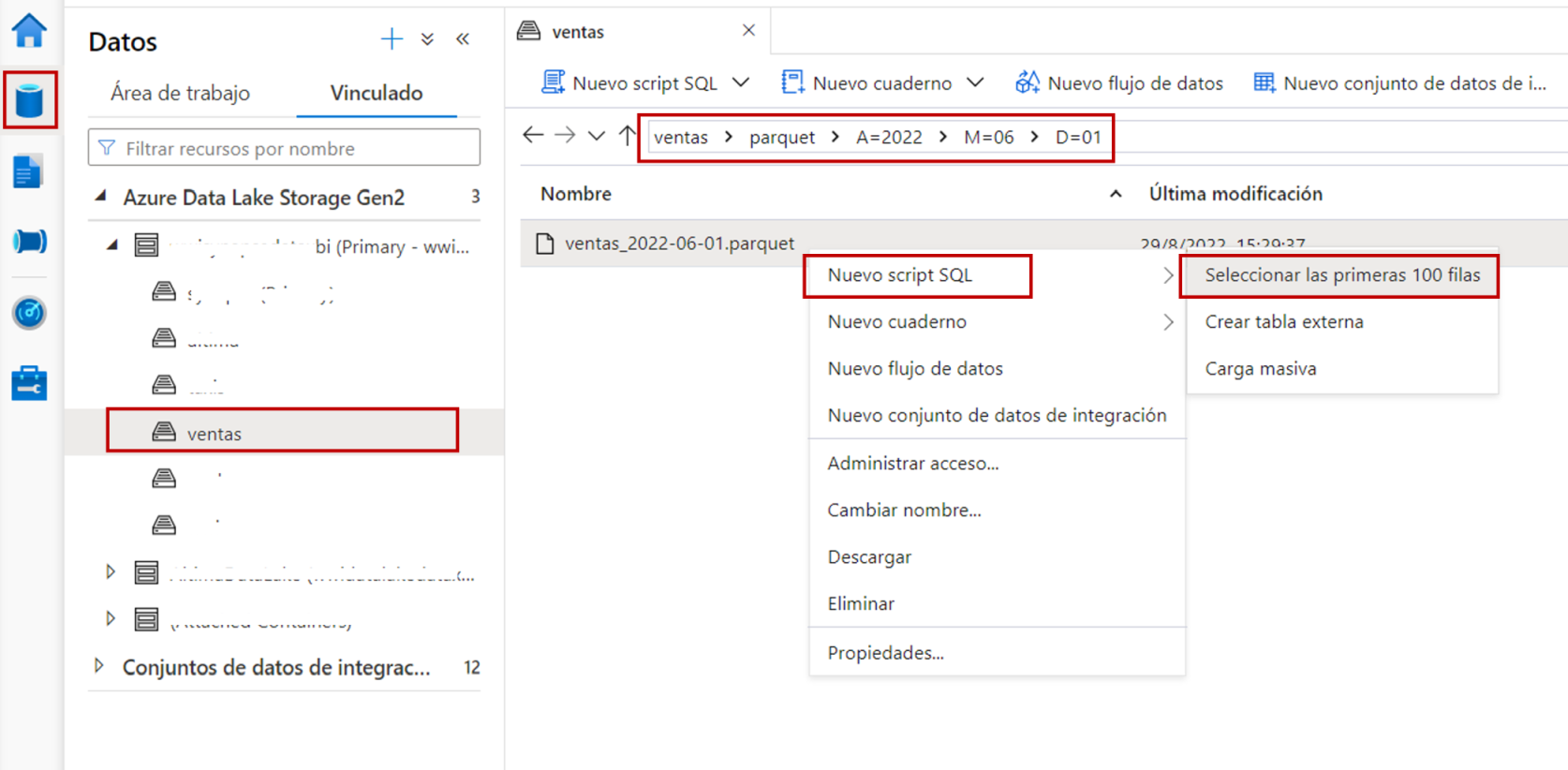
Esto nos abrirá un nuevo editor de SQL con una consulta que utiliza OPENROWSET con el formato PARQUET, para acceder al archivo Parquet y mostrar las 100 primeras filas. Si ejecutamos la consulta, podemos ver que devuelve todas las columnas del archivo Parquet con el tipo de dato correspondiente. Recuerda que esta información está guardada en los metadatos del archivo Parquet.
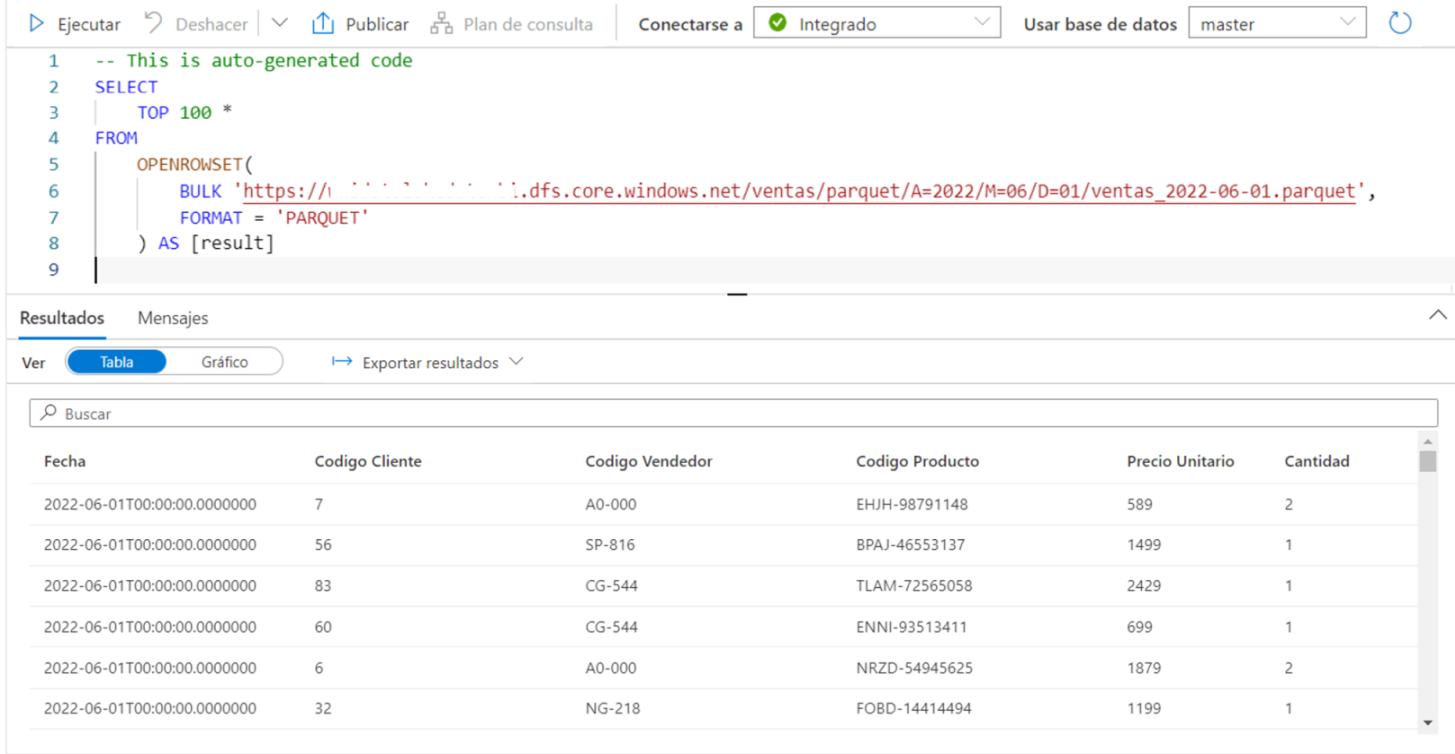
Para saber cuantos datos fueron procesados por esta consulta y así poder tener una idea del coste, podemos mirar en la pestaña de mesajes del editor de SQL.

La consulta ha necesitado escanear 6 MB del archivo Parquet y ha movido 1 MB, por lo que el total procesado es de 7 MB. Los datos movidos incluyen los que se han enviado para mostrar los resultados. Recuerda que el archivo tiene 20 MB. O sea, para esta consulta no se ha tenido que leer todo el archivo Parquet!!!
Si queremos conocer con más exactitud cuanto nos cobrará Azure por la consulta, en Synapse Studio podemos ir a la hoja Monitor y seleccionar la opción Solicitudes de SQL para ver qué volumen de datos procesados nos reporta Synapse.

Synapse nos reporta que en esta consulta se procesaron 10 MB, a pesar que en realidad fueron 7 MB, porque 10 MB es el cargo mínimo. El coste para la región Oeste de Europa es de €4,756 * 10 / 1.000.000 = €0,0004756 asumiendo que 1 TB equivale a 1 millón de MB.
Para dar una idea de cómo influyen algunos filtros en el coste, he probado varias consultas y he revisado el mensaje del editor de SQL y los datos procesados reportados por Monitor y he construido la siguiente tabla.
| Consulta SQL | Comentarios | Mensaje del editor de SQL | Datos procesados reportados por Monitor |
|---|---|---|---|
| SELECT TOP 100 * FROM … | Lista las 100 primeras filas, todas las columnas | Datos escaneados: 6 MB Datos movidos: 1 MB | 10 MB |
| SELECT TOP 100 [Fecha], [Codigo Cliente], [Precio Unitario], [Cantidad] FROM … | Lista las 100 primeras filas, algunas columnas | Datos escaneados: 4 MB Datos movidos: 1 MB | 10 MB |
| SELECT COUNT(*) FROM … | Cuenta el total de filas | Datos escaneados: 1 MB Datos movidos: 1 MB | 10 MB |
| SELECT * FROM … | Lista todas las filas y todas las columnas | Datos escaneados: 21 MB Datos movidos: 206 MB | 227 MB |
| SELECT [Fecha], [Codigo Cliente], [Precio Unitario], [Cantidad] FROM … | Lista todas las filas y algunas columnas | Datos escaneados: 12 MB Datos movidos: 84 MB | 96 MB |
| SELECT * FROM … WHERE [Codigo Cliente] = 70 | Lista las filas del cliente con el código 70, todas las columnas | Datos escaneados: 21 MB Datos movidos: 3 MB | 24 MB |
| SELECT [Fecha], [Codigo Cliente], [Precio Unitario], [Cantidad] FROM … WHERE [Codigo Cliente] = 70 | Lista las filas del cliente con el código 70, algunas columnas | Datos escaneados: 12 MB Datos movidos: 1 MB | 13 MB |
En esta tabla se pueden ver más ejemplos donde no es necesario escanear el archivo Parquet completo: cuando se hace una agregación como COUNT, cuando se utiliza TOP para leer las primeras filas, cuando se seleccionan algunas columnas.
También vemos que aunque se filtren las filas por el código del cliente, se lee todo el archivo, pero esto sucede porque este archivo es relativamente pequeño, con archivos Parquet más grandes también va a pasar que al filtrar filas no es necesario escanearlo todo.
Otra concluisón que se puede sacar de la tabla es cómo influye en el coste final el volumen de datos devueltos.
Para terminar, voy a crear una vista SQL que acceda a todos los archivos Parquet y que se podrá usar desde Power BI.
Usaré la misma base de datos ventas y el mismo origen de datos externo VentasDS creados en la entrada de blog anterior.
CREATE VIEW vwVentasParquet
AS
SELECT
v.*,
CAST(v.filename() AS varchar(25)) AS 'Archivo',
CAST(v.filepath(1) AS INT) AS 'Año',
CAST(v.filepath(2) AS TINYINT) AS 'Mes',
CAST(v.filepath(3) AS TINYINT) AS 'Dia'
FROM
OPENROWSET (
BULK 'parquet/A=*/M=*/D=*/*.parquet',
DATA_SOURCE = 'VentasDS',
FORMAT = 'PARQUET'
)
WITH (
Fecha DATE,
[Codigo Cliente] INT,
[Codigo Vendedor] CHAR(6) COLLATE Latin1_General_100_BIN2_UTF8,
[Codigo Producto] CHAR(13) COLLATE Latin1_General_100_BIN2_UTF8,
[Precio Unitario] FLOAT,
Cantidad INT
)
AS v
La vista se parece mucho a la utilizada para los archivos CSV, con la diferencia que en OPENROWSET se utiliza el formato PARQUET.
Aunque en el caso de Parquet se conoce el tipo de datos de cada columna porque está en los metadatos, se recomienda también el uso de la instrucción WITH para indicar de manera explícita los tipos de datos y así utilizar los más pequeños posibles.
Además, si hay columnas de texto es muy importante indicar la colación Latin1_General_100_BIN2_UTF8 que es la única que en estos momentos es compatible con el formato Parquet y que garantiza que los textos se visualicen correctamente, que disminuya el volumen de datos procesados y que haya mejor rendimiento.
También se usan las funciones filename() y filepath() que expliqué en la entrada de blog anterior. Recuerda que el valor del parámetro que se le pasa a filepath() está relacionado con la posisición de los asteriscos en la ruta a los archivos indicada en OPENROWSET. Por lo que filepath(1) corresponde al año, filepath(2) al mes y filepath(3) al día.
Para demostrar el impacto que tiene filtrar usando las columnas que utilizan filepath(), que son Año, Mes y Dia, en lugar de usar la columna Fecha, voy a ejecutar dos consultas SQL y comparar cuantos datos son procesados en cada caso.
Primero vamos a ejecutar la siguiente consulta SQL:
SELECT COUNT(*)
FROM vwVentasParquet
WHERE Fecha = '2022-05-01'
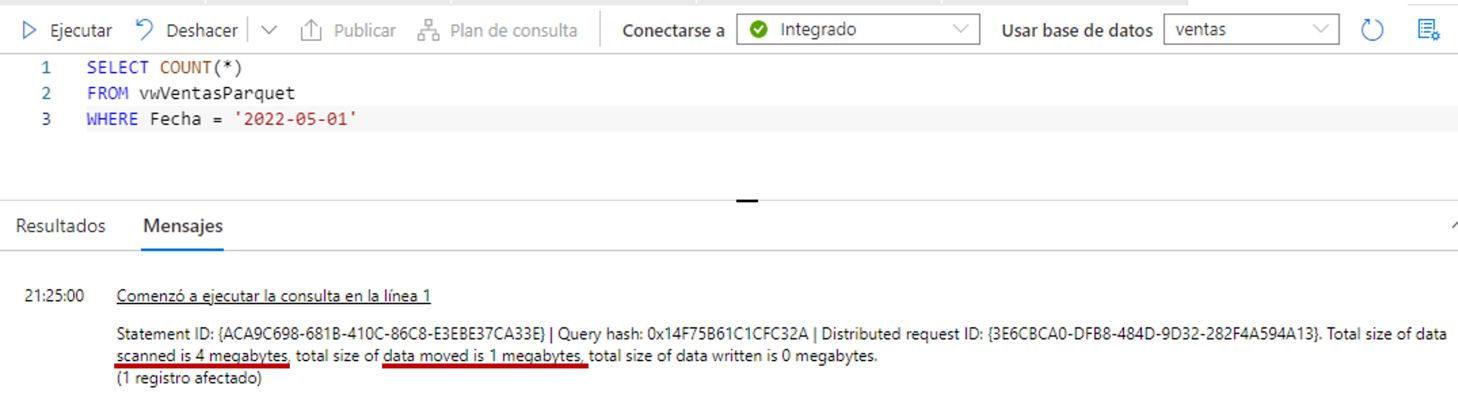
Podemos ver en la imagen que se escanean 4 MB y se mueve 1 MB.
A continuación ejecutamos la consulta:
SELECT COUNT(*)
FROM vwVentasParquet
WHERE [Año] = 2022 AND [Mes] = 5 AND [Dia] = 1
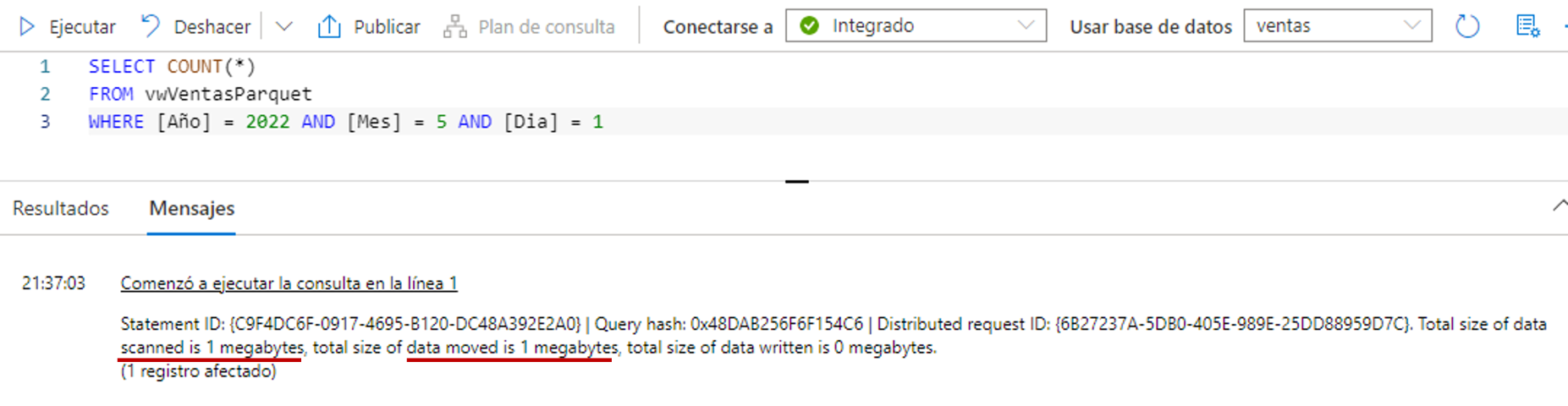
Y podemos ver en la imagen que se escanea 1 MB y se mueve 1 MB.
La disminución de los datos escaneados cuando se usan las columnas con filepath() se logra por la poda de partición (partition pruning) ya que sólo se procesan datos de los archivos que están en la ruta filtrada,en este caso sería un sólo archivo. Mientras que en la primera consulta donde se filtra con la columna Fecha se busca información en todos los archivos.
Faltaría ir a Power BI Desktop para conectarnos con esta vista, pero se haría exactamente de la misma manera que con los archivos CSV, con la uníca diferencia en el nombre de la vista.
Bueno, lo dejo aquí y espero que te sea útil.