Carga de datos hacia Azure Synapse Analytics (SQL Data Warehouse) con PolyBase
PolyBase extiende T-SQL para permitir consultas a datos alojados en fuentes externas. En esta entrada cargaremos un archivo CSV con unas 2.5 millones de filas, alojado en Azure Data Lake Store Gen2 hacia una tabla en un almacén de datos en Azure Synapse Analytics (SQL Data Warehouse).
El archivo es el mismo utilizado en una entrada anterior, y contiene datos de los vuelos comerciales dentro de los Estados Unidos entre julio y octubre de 2019
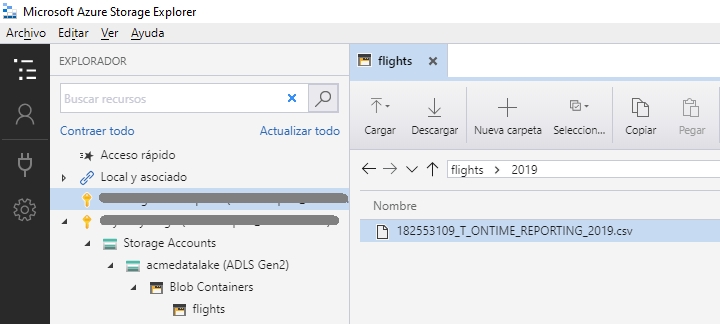
En Azure he creado una nueva cuenta de almacenamiento, del tipo StorageV2 y en las opciones avanzadas he habilitado el espacio de nombre jerárquico, para de esta forma crear un Data Lake Gen2. Después he creado un contenedor con el nombre flights y dentro de él he creado la carpeta 2019 y he subido hacia ella el archivo CSV. Es recomendable acceder a las cuentas de almacenamiento de Azure utilizando la herramienta gratuita Azure Storage Explorer.
También he creado en Azure un recurso Synapse Analytics (SQL Data Warehouse) y ahora utilizaré PolyBase para cargar el archivo. Para ello hay que empezar creando una tabla externa, que tenga como fuente de datos Azure Data Lake, y con el formato de datos apropiado.
Para crear la fuente de datos externa he utilizado los siguientes comandos T-SQL (PolyBase):
CREATE MASTER KEY;
Si la base de datos ya tiene una master key, no es necesario ejecutarlo.
CREATE DATABASE SCOPED CREDENTIAL DataLakeCredential
WITH
IDENTITY = 'user',
SECRET = 'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'
;
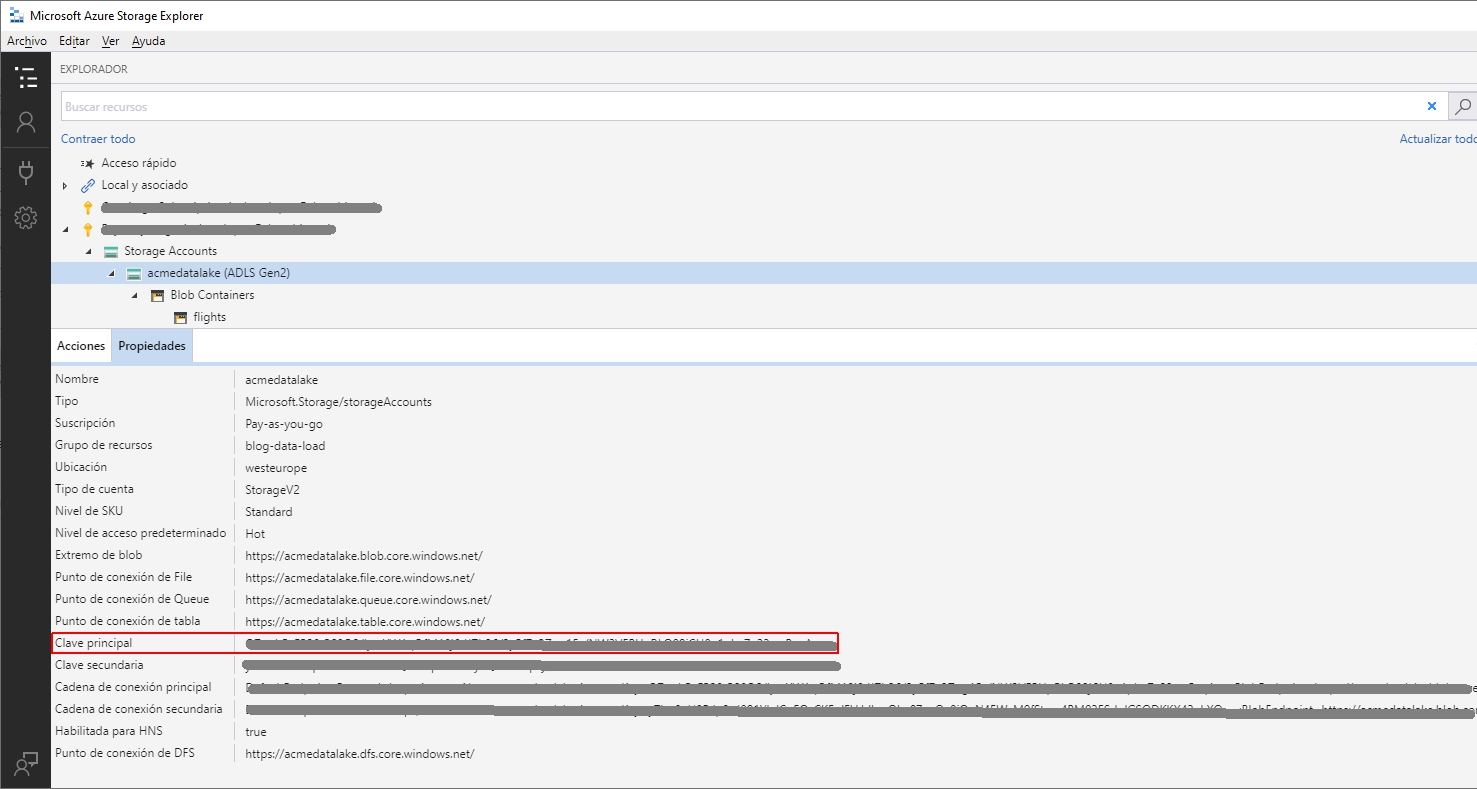
Aquí se guardan las credenciales para acceder al Data Lake, y en este caso utilizaré una clave compartida de la cuenta de almacenamiento (ver imagen) que se copia en SECRET. En IDENTITY se puede utilizar un valor arbitrario.
CREATE EXTERNAL DATA SOURCE DataLakeStorage
WITH (
TYPE = HADOOP,
LOCATION='abfss://flights@acmedatalake.dfs.core.windows.net',
CREDENTIAL = DataLakeCredential
);
Aquí se crea la fuente de datos externa con el nombre DataLakeStorage, utilizando las credenciales almacenadas antes, DataLakeCredential. Azure Data Lake Gen2 implementa un sistema de archivo compatible con HADOOP, por lo que en la configuración de la fuente de datos se utiliza el tipo HADOOP. En LOCATION se utiliza el protocolo abfss://, con una s extra al final porque al crear la cuenta de almacenamiento indicamos el valor por defecto de sólo permitir transferencias seguras. flights es el nombre del contenedor y acmedatalake es el nombre da la cuenta de almacenamiento.
Para crear el formato de datos he utilizado el siguiente comando:
CREATE EXTERNAL FILE FORMAT CsvFileFormat
WITH
(
FORMAT_TYPE = DELIMITEDTEXT,
FORMAT_OPTIONS
(
FIELD_TERMINATOR = ',',
STRING_DELIMITER = '"',
FIRST_ROW = 2
)
);
El nombre del formato es CsvFileFormat y los parámetros indican que es un archivo texto con la coma (,) delimitando los campos y las dobles comillas delimitando las cadenas de caracteres, y que empiece a leer los datos a partir de la segunda fila, porque la primera es de encabezados.
Para crear la tabla externa he utilizado el siguiente comando:
CREATE EXTERNAL TABLE [dbo].[StgFlights_external] (
FL_DATE date,
OP_UNIQUE_CARRIER char(2),
OP_CARRIER_FL_NUM int,
ORIGIN_AIRPORT_ID int,
ORIGIN char(3),
ORIGIN_CITY_NAME varchar(40),
ORIGIN_STATE_ABR char(2),
DEST_AIRPORT_ID int,
DEST char(3),
DEST_CITY_NAME varchar(40),
DEST_STATE_ABR char(2),
CRS_DEP_TIME char(4),
DEP_TIME char(4),
DEP_DELAY decimal(8,2),
CRS_ARR_TIME char(4),
ARR_TIME char(4),
ARR_DELAY decimal(8,2),
CANCELLED char(4),
CANCELLATION_CODE char(1),
DIVERTED char(4)
)
WITH
(
LOCATION ='/2019/',
DATA_SOURCE = DataLakeStorage,
FILE_FORMAT = CsvFileFormat,
REJECT_TYPE = VALUE,
REJECT_VALUE = 0
);
El nombre de la tabla externa es StgFlights_external y los campos coinciden con las columnas del CSV. DATA_SOURCE y FILE_FORMAT tienen el nombre de la fuente de datos y del formato que creamos antes. LOCATION apunta a la capeta que creamos en el Data Lake, por lo que todos los archivos contenidos en esa carpeta formaran parte de la la tabla externa. REJECT_TYPE y REJECT_VALUE indican cuantos errores se toleran antes de abortar la carga, en este caso ninguno.
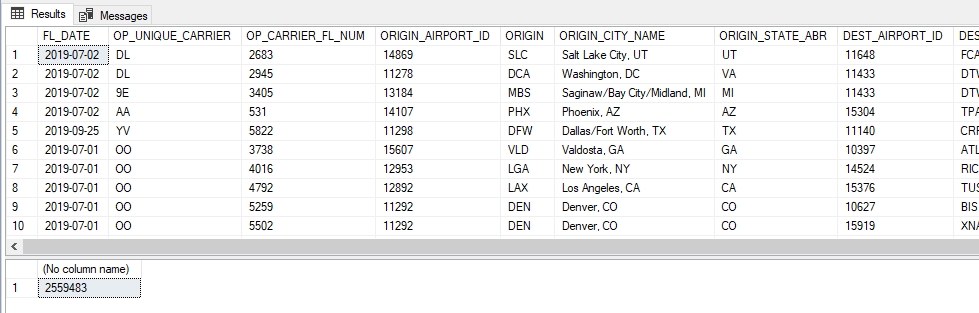
Consultamos la tabla externa para estar seguro de que se pueden leer los datos. Tenga en cuenta que estos datos no están almacenados en la base de datos, sino en el Data Lake.
SELECT TOP 300 * FROM [DBO].[STGFLIGHTS_EXTERNAL]
SELECT COUNT(*) FROM [DBO].[STGFLIGHTS_EXTERNAL]
Para cargar los datos hacia una tabla, utilizo un comando CTAS (Create Table As Select)
CREATE TABLE [dbo].[StgFlights]
WITH (DISTRIBUTION = ROUND_ROBIN )
AS
SELECT * FROM [dbo].[StgFlights_external]
Si una vez ejecutado el comando, repetimos las consultas que hicimos a la tabla externa, debemos obtener el mismo resultado.
En Azure Synapse Analytics cada almacén de datos se separa en 60 distribuciones, que se reparten entre los nodos disponibles.
Por ejemplo:
- con 100 unidades de almacenamiento (DWU), sólo hay 1 nodo, que contendrá las 60 distribuciones
- con 1000 DWU, hay 2 nodos, por lo que cada uno tendrá 30 distribuciones
Si los datos están divididos en varios archivos, estos se podrán procesar en paralelo, mejorando el rendimiento de la carga.
Para comprobarlo, separé el archivo CSV en 4 y repetí la carga de datos con distinta configuración, y medí el tiempo.
| DWU | Archivos | Tiempo |
|---|---|---|
| 100 DWU (1 nodo) | 1 | 34 seg |
| 100 DWU (1 nodo) | 4 | 31 seg |
| 1000 DWU (2 nodos) | 1 | 9 seg |
| 1000 DWU (2 nodos) | 4 | 4 seg |